Top 5 câu hỏi phỏng vấn Big Data Engineer hay gặp nhất 2024
Phỏng vấn Big Data Engineer liệu có khó? Có phải Big là luôn đặt ra những câu hỏi hóc búa dành cho ứng viên phỏng vấn Big Data Engineer?
Câu trả lời là không, bất kì vị trí nào cũng có các topics cần và sẽ hỏi qua. Đơn cử như Big data engineer thì đó sẽ là các câu hỏi liên quan tới kỹ năng, khả năng xử lý dữ liệu.
Ngoài ra các công cụ thường được sử dụng cũng sẽ là câu hỏi đáng lưu tâm khi phỏng vấn vị trí này.

Chi tiết mời anh em cùng tìm hiểu qua 5 câu hỏi dưới đây. Bắt đầu ngay thôi nào!
1. Làm việc với dữ liệu, bạn xử lý duplicate data như thế nào?
Câu hỏi đầu tiên phỏng vấn Big Data Engineer đề cập tới SQL. Đã là làm việc với dữ liệu tất nhiên sẽ làm việc với dữ liệu được lưu ở các RDBMS.
Làm việc với RDBMS tất nhiên sẽ biết tới SQL, một trong những hiểu biết cơ bản để làm việc với dữ liệu. Câu hỏi này được đánh giá là câu hỏi dễ do chỉ xử lý dữ liệu trùng lặp.
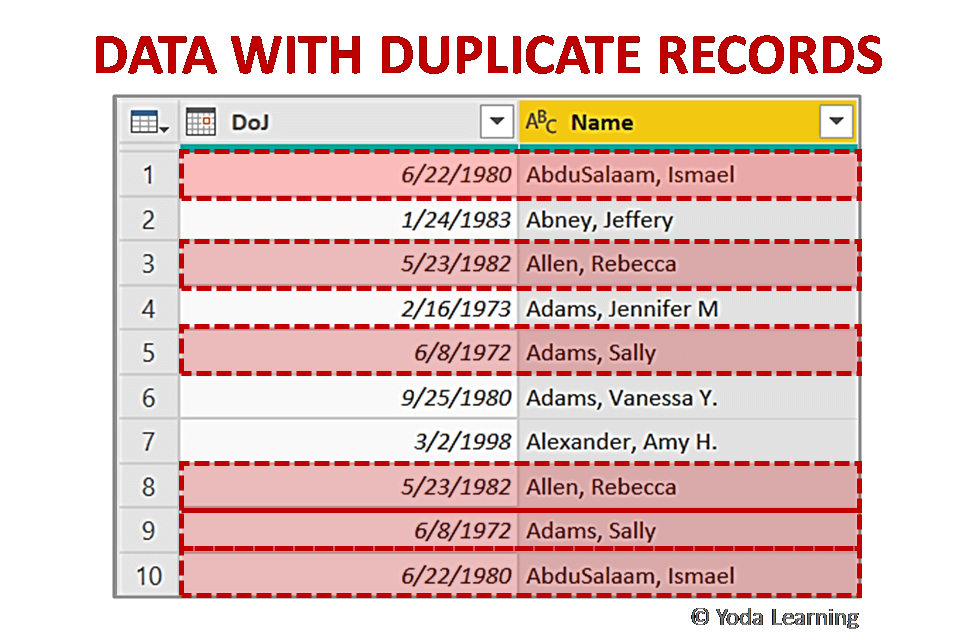
Trả lời cho câu hỏi này, có nhiều cách để xử lý trùng lặp dữ liệu. Bao gồm sử dụng một số từ khoá phổ biến trong SQL. Một số keywords phổ biến bao gồm DISTINCT và UNIQUE.
Ngoài ra một số loại dữ liệu có thể sử dụng GROUP BY để loại bỏ trùng lặp.
Anh em có thể chuẩn bị thêm các câu hỏi sau:
-
- Sự khác biệt giữa tuples và list là gì?
-
- *args và *kwargs là gì?. Sự khác biệt?
-
- Distributed file system là gì?
2. Những frameworks và ngôn ngữ nào thường được sử dụng bởi Big Data Engineer
Khởi động với câu hỏi dễ dàng đầu tiên phỏng vấn Big Data Engineer. Thông thường các kỹ sư dữ liệu lớn sẽ làm việc với một số frameworks, tools và ngôn ngữ lập trình nhất định.
Thường trong giới big data có các tools, framework của riêng mình để làm việc với dữ liệu lớn. Việc sử dụng thành thạo các công cụ cũng đồng nghĩa với việc ứng viên có khả năng có nhiều kinh nghiệm làm việc trong dự án thực tế.
Đối với câu hỏi này, anh em có thể liệt kê 3 công cụ chính thường được sử dụng bởi Big Data Engineer bao gồm:
-
- Hadoop
Ngoài ra, dựa theo kinh nghiệm thực tế, anh em có thể bổ sung một số công cụ sau:
-
- ElasticSearch
Ngoài ra, cần đi sâu các trường hợp cụ thể sử dụng, ví dụ Postgres, nếu thường xuyên làm việc với geospatial, anh em có thể nêu ra những cái tên cụ thể như PostGIS.
3. Sự khác biệt giữa dữ liệu có cấu trúc và dữ liệu không có cấu trúc
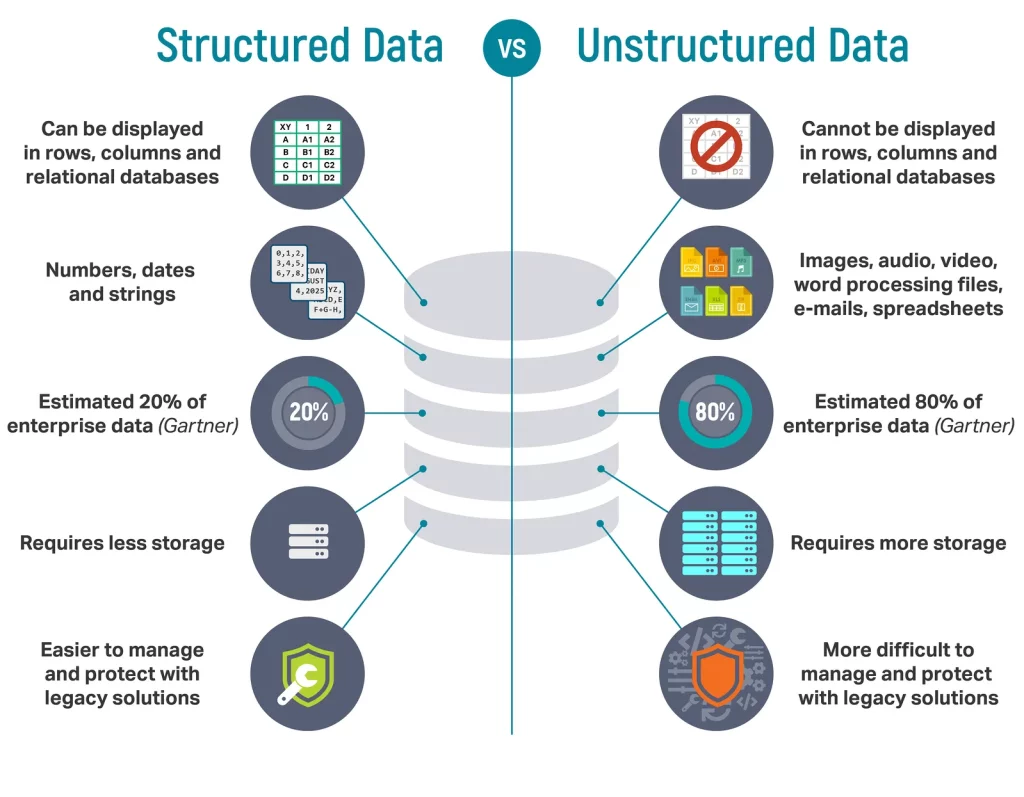
Câu hỏi phỏng vấn Big Data Engineer thứ hai liên quan tới data. Đã là kỹ sư dữ liệu tất nhiên sẽ làm việc nhiều với dữ liệu. Vậy sự khác biệt giữa dữ liệu có cấu trúc (structured data) và dữ liệu không có cấu trúc (unstructured data) là gì?
Để trả lời cho câu hỏi này, anh em có thể nêu ra một số sự khác biệt chính giữa hai loại dữ liệu này bao gồm:
-
- Dữ liệu có cấu trúc (structured data) yêu cầu công cụ tích hợp ELT và được lưu trữ vào DBMS (hệ thống quản lý cơ sở dữ liệu) hoặc dữ liệu dạng bảng.
-
- Dữ liệu phi cấu trúc (unstructured data) có hướng tiếp cận khác với dữ liệu, space (không gian) lưu trữ thường nhiều hơn so với dữ liệu cấu trúc
-
- Ngoài ra dữ liệu phi cấu trúc (unstructured) thường khó để mở rộng, trong khi dữ liệu có cấu trúc thường dễ mở rộng hơn.
Anh em có thể chuẩn bị thêm hoặc ôn lại các câu hỏi sau:
-
- Bạn định nghĩa big data như thế nào? (hoặc như thế nào là big data).
-
- Data modeling là gì?
-
- Những softskill nào là quan trọng đối với Big Data Engineer…
4. Bạn deploy giải pháp big data như thế nào?
Câu hỏi thứ 4 phỏng vấn Big Data Engineer đề cập tới quy trình khi đã có giải pháp xử lý dữ liệu lớn. Về cơ bản câu hỏi này đánh vào kinh nghiệm thực tế làm việc trong các dự án.
Có 3 bước cơ bản để deploy big data solutions, tuy nhiên anh em có thể thoải mái nêu thêm các bước bổ sung như kiểm tra dữ liệu, chuẩn bị dữ liệu,…
Ngoài ra ở các bước, anh em còn có thể nêu kinh nghiệm thực tế của bản thân mình, càng cụ thể thì càng tốt. Quay lại với 3 bước deploy:
-
- Ingest and extract the data from each source, such as Oracle or MySQL (nhập và trích xuất dữ liệu từ các nguồn khác nhau, ví dụ như Oracle hoặc MySQL.
-
- Store the data in HDFS or HBase (lưu trữ dữ liệu trong HDFS hoặc HBase)
-
- Process the data by using a framework such as Hive or Spark (xử lý dữ liệu bằng các framework như Hive hoặc Spark)
Một số câu hỏi anh em có thể chuẩn bị thêm:
-
- Core feature của Hadoop là gì?
-
- Giải thích FSCK (file system check)?
-
- Collection data types nào Hive hỗ trợ (Map, Struct, Array)
5. Những library nào thường sử dụng trong Python để xử lý dữ liệu
Câu hỏi cuối cùng phỏng vấn Big Data Engineer liên quan tới các thư viện thường được sử dụng để xử lý dữ liệu.
Cái này thì tuỳ kinh nghiệm làm việc anh em có thể nêu ra các thư viện mình thường sử dụng. Ngoài ra cũng có thể nói thêm các điểm mạnh, điểm yếu. Những bất cập có thể xảy ra trong quá trình sử dụng các library này.
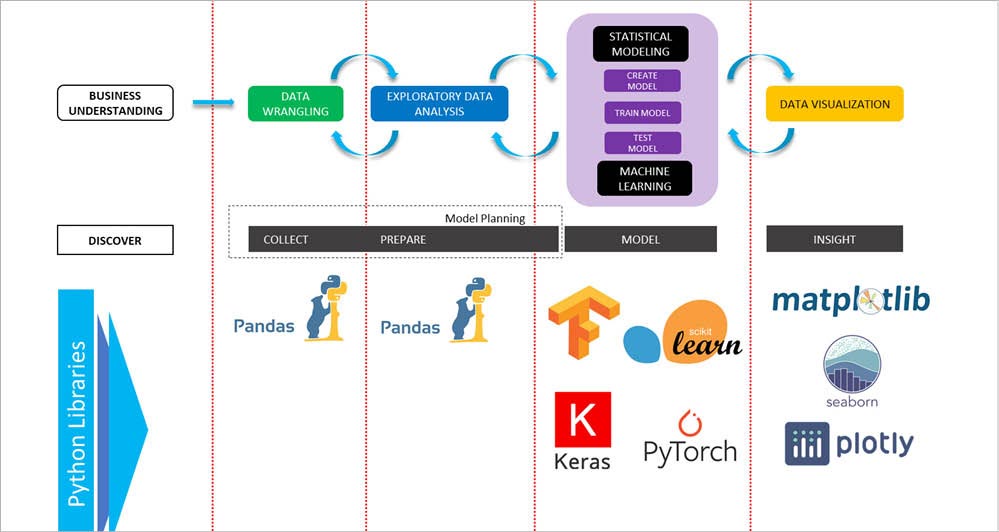
Danh sách một số library anh em có thể liệt kê ra. Cũng có thể chia nhóm library theo từng mục đích sử dụng.
-
- SciKit-Learn
-
- NumPy
-
- Pandas
Anh em cũng có thể chuẩn bị thêm các câu hỏi sau:
-
- File permission trong Hadoop là gì?
-
- Nếu chỉ có 1 file duy nhất, có thể tạo nhiều bảng cho 1 file dữ liệu đó không?
-
- Big data trên cloud có gì đặc biệt? Điểm mạnh, điểm yếu như thế nào?
6. Tham khảo thêm phỏng vấn Big Data Engineer
Cảm ơn anh em đã đọc bài – Thank you for your time – Happy coding!
Tác giả: Kiên Nguyễn
Bài viết liên quan

Big Data có thật sự “toàn năng” và các cơ hội nghề nghiệp trong tương lai?

Khám phá Quy trình tuyển dụng Data Engineer

Tại sao lập trình viên nên học cấu trúc dữ liệu và giải thuật?
Xem thêm Top Việc làm IT trên TopDev
- N Ngành nào đang khát nhân lực tại Việt Nam? (2025)
- T Top 10 ngành nghề cho sinh viên mới tốt nghiệp 2025: Bắt đầu từ đâu giữa thời đại chuyển mình?
- L Lộ trình phát triển sự nghiệp cho người muốn đổi ngành
- A Agency và Client trong tổng quan ngành Marketing: Người mới bắt đầu cần hiểu gì?
- M Marketing từ con số 0: Lộ trình chi tiết, rõ ràng cho người mới bắt đầu
- L Làm thêm giờ là tốt hay xấu? Tips OT hiệu quả hơn
- 7 7 vị trí CNTT không cần code giỏi mà vẫn thành công
- B Bức tranh toàn cảnh hệ sinh thái khởi nghiệp công nghệ Việt Nam 2024
- R Reskill là gì? Sự khác nhau giữa Reskill và Upskill
- U Upskill là gì? 5 cách Upskilling bản thân hiệu quả