Sử dụng Machine Learning trên Compute Engine để recommend sản phẩm (phần 2)
Phần 1
Cung cấp các recommendations
Để làm cho kết quả của người dùng nhanh chóng và dễ dàng, bạn cần phải tải chúng vào cơ sở dữ liệu có thể được truy vấn theo yêu cầu. Một lần nữa, Cloud SQL là một lựa chọn tuyệt vời ở đây. Từ Spark 1.4, bạn có thể ghi các kết quả của dự đoán trực tiếp vào cơ sở dữ liệu từ PySpark.
Lược đồ của bảng Recommendation như sau:
CREATE TABLE Recommendation
(
userId varchar(255),
accoId varchar(255),
prediction float,
PRIMARY KEY(userId, accoId),
FOREIGN KEY (accoId)
REFERENCES Accommodation(id)
);
Code walkthrough
Phần này sẽ code để train các mô hình.
Lấy dữ liệu từ Cloud SQL
Spark SQL cho phép bạn dễ dàng kết nối với một Cloud SQL instance qua kết nối JDBC. Dữ liệu được tải là ở định dạng DataFrame
jdbcUrl = 'jdbc:mysql://%s:3306/%s?user=%s&password=%s' % (CLOUDSQL_INSTANCE_IP, CLOUDSQL_DB_NAME, CLOUDSQL_USER, CLOUDSQL_PWD) dfAccos = sqlContext.read.jdbc(url=jdbcUrl, table=TABLE_ITEMS) dfRates = sqlContext.read.jdbc(url=jdbcUrl, table=TABLE_RATINGS)
Chuyển đổi DataFrame sang RDD và tạo ra các bộ dữ liệu khác nhau
Spark sử dụng một khái niệm được gọi là RDD (Resilient Distributed Dataset), tạo điều kiện thuận lợi cho việc làm việc với các elements song song. RDDs là bộ sưu tập chỉ đọc được tạo từ bộ nhớ lưu trữ liên tục. Chúng có thể được xử lý trong bộ nhớ, vì vậy chúng rất thích hợp cho quá trình xử lý lặp.
Để có được mô hình tốt nhất cho dự đoán của bạn, bạn cần chia các bộ dữ liệu của mình thành ba bộ khác nhau. Đoạn mã sau sử dụng một chức năng trợ giúp ngẫu nhiên phân chia các giá trị không chồng chéo trên cơ sở tỷ lệ phần trăm 60/20/20:
rddTraining, rddValidating, rddTesting = dfRates.rdd.randomSplit([6,2,2])
Lưu ý: Điều quan trọng là tạo bảng Rating với các cột theo thứ tự sau: accoId, userId, rating. ALS cần làm việc với các cặp sản phẩm-người dùng xác định để dự đoán. Bạn có thể sửa đổi cơ sở dữ liệu của mình hoặc sử dụng call tới map trên RDD để sắp xếp các cột đúng cách.
Train các mô hình dựa trên các thông số khác nhau
Khi sử dụng phương pháp ALS, hệ thống cần phải làm việc với các thông số xếp hạng, định chuẩn, và lặp lại để tìm ra mô hình tốt nhất. Các xếp hạng tồn tại, vì vậy các kết quả của train phải được so sánh với bộ xác nhận. Bạn muốn đảm bảo rằng xu hướng của người dùng cũng nằm trong tập huấn luyện.
for cRank, cRegul, cIter in itertools.product(ranks, reguls, iters):
model = ALS.train(rddTraining, cRank, cIter, float(cRegul))
dist = howFarAreWe(model, rddValidating, nbValidating)
if dist < finalDist:
print("Best so far:%f" % dist)
finalModel = model
finalRank = cRank
finalRegul = cRegul
finalIter = cIter
finalDist = dist
Lưu ý: Hàm howFarAreWe sử dụng mô hình dự đoán xếp hạng trên tập dữ liệu xác thực, chỉ sử dụng các cặp sản phẩm – người dùng.
def howFarAreWe(model, against, sizeAgainst): # Ignore the rating column againstNoRatings = against.map(lambda x: (int(x[0]), int(x[1])) ) # Keep the rating to compare against againstWiRatings = against.map(lambda x: ((int(x[0]),int(x[1])), int(x[2])) ) # Make a prediction and map it for later comparison # The map has to be ((user,product), rating) not ((product,user), rating) predictions = model.predictAll(againstNoRatings).map(lambda p: ( (p[0],p[1]), p[2]) ) # Returns the pairs (prediction, rating) predictionsAndRatings = predictions.join(againstWiRatings).values() # Returns the variance return sqrt(predictionsAndRatings.map(lambda s: (s[0] - s[1]) ** 2).reduce(add) / float(sizeAgainst))
Tính các dự đoán hàng đầu cho người dùng
Bây giờ bạn có một mô hình có thể đưa ra một dự đoán hợp lý, bạn có thể sử dụng nó để xem những gì người dùng có thể quan tâm nhất dựa trên sở thích và xếp loại của họ bởi những người khác có cùng sở thích. Trong bước này, bạn có thể thấy bản đồ ma trận đã được mô tả trước đó.
# Build our model with the best found values
# Rating, Rank, Iteration, Regulation
model = ALS.train(rddTraining, BEST_RANK, BEST_ITERATION, BEST_REGULATION)
# Calculate all predictions
predictions = model.predictAll(pairsPotential).map(lambda p: (str(p[0]), str(p[1]), float(p[2])))
# Take the top 5 ones
topPredictions = predictions.takeOrdered(5, key=lambda x: -x[2])
print(topPredictions)
schema = StructType([StructField("userId", StringType(), True), StructField("accoId", StringType(), True), StructField("prediction", FloatType(), True)])
dfToSave = sqlContext.createDataFrame(topPredictions, schema)
dfToSave.write.jdbc(url=jdbcUrl, table=TABLE_RECOMMENDATIONS, mode='overwrite')
Lưu các dự đoán hàng đầu
Bây giờ bạn có một danh sách tất cả các dự đoán, bạn có thể lưu top 10 trong Cloud SQL để hệ thống có thể đưa ra một số đề xuất cho người dùng. Ví dụ, thời điểm tốt để sử dụng những dự đoán này có thể là khi người dùng đăng nhập vào trang web.
dfToSave = sqlContext.createDataFrame(topPredictions, schema) dfToSave.write.jdbc(url=jdbcUrl, table=TABLE_RECOMMENDATIONS, mode='overwrite')
Thực hiện các giải pháp
Để chạy giải pháp này, hãy làm theo hướng dẫn từng bước trên trang GitHub. Làm theo hướng dẫn, bạn sẽ có thể tính toán và hiển thị các đề xuất cho người dùng.
Mã SQL cuối cùng lấy yêu cầu hàng đầu từ cơ sở dữ liệu và hiển thị nó trên trang chào mừng của Samantha.
Truy vấn, khi chạy trong Cloud Platform Console mây hoặc MySQL khách, trả về kết quả tương tự như ví dụ sau:
Trong trang web, cùng một truy vấn có thể nâng cao trang chào mừng và tăng khả năng chuyển đổi khách truy cập cho khách hàng:
Giám sát công việc
Giám sát với thiết lập bdutil
Bạn đã sử dụng SSH để kết nối với ví dụ chính. Khi bạn bắt đầu điều hành công việc, điều quan trọng là có thể giám sát họ. Spark cung cấp một giao diện điều khiển quản lý mà bạn có thể sử dụng trong trình duyệt.
Console chạy theo mặc định trên cổng 8080, bạn phải mở trong tường lửa cho từng trường hợp bằng cách làm theo các bước này. Bạn có thể mở giao diện điều khiển bằng cách sử dụng IP external của instance trong URL: http://1.2.3.4:8080, ví dụ. Trong ảnh chụp màn hình sau, bạn có thể thấy hai worker được liệt kê, các ứng dụng đang chạy và những ứng dụng đã hoàn thành, Spark được dùng trong trường hợp này.
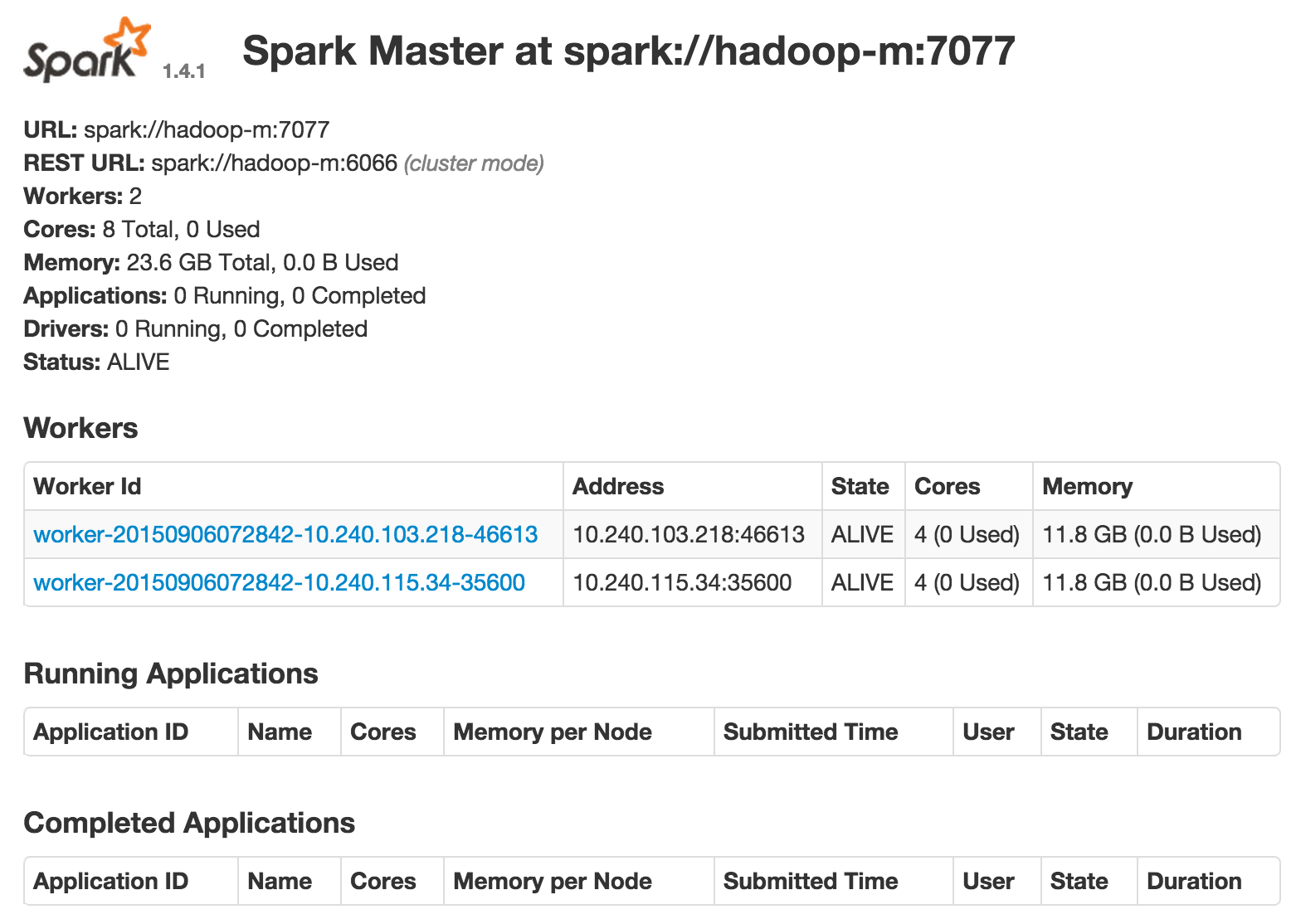
The Spark console
Theo dõi với Cloud Dataproc
Xem tài liệu Cloud Dataproc để tìm hiểu thêm về output hoặc web interfaces.
Tutorial
Toàn bộ nội dung tutorial, gồm các hướng dẫn setup và source code trên GitHub.
Các bước tiếp theo
- Hãy thử các tính năng khác của Google Cloud Platform cho chính bạn. Hãy xem hướng dẫn của chúng tôi.
- Tìm hiểu cách sử dụng các sản phẩm của Google Cloud Platform để xây dựng giải pháp end-to-end
Phụ lục
Cross filtering
Mặc dù bạn đã thấy cách xây dựng giải pháp collaborative filter hiệu quả và có thể mở rộng, vượt qua các kết quả với các loại lọc khác có thể cải thiện đề xuất. Nhớ lại hai loại lọc chính khác: dựa vào content-based và clustering. Một sự kết hợp của những cách tiếp cận này có thể tạo ra một khuyến cáo tốt hơn cho người sử dụng.
Content-based filtering
Lọc dựa trên nội dung hoạt động trực tiếp với các thuộc tính và hiểu được những điểm tương đồng của chúng, giúp tạo ra các đề xuất cho các mục có cùng thuộc tính nhưng có ít xếp hạng của người dùng. Khi cơ sở người dùng phát triển, loại lọc này vẫn có thể quản lý được, ngay cả với một số lượng lớn người dùng.
Để thêm lọc dựa trên nội dung, bạn có thể sử dụng xếp hạng trước đó của người dùng khác cho các mục trong danh mục. Dựa trên các xếp hạng này, bạn có thể tìm thấy những sản phẩm tương tự nhất với sản phẩm hiện tại.
Một cách phổ biến để tính sự giống nhau giữa hai sản phẩm là sử dụng sự giống nhau giữa cô sin và tìm những tính chất gần nhất:
Kết quả tương tự sẽ là từ 0 đến 1. Gần đến 1, các sản phẩm càng giống nhau.
Trong ma trận này, sự tương tự giữa P1 và P2 có thể được tính như sau:
Bạn có thể lọc được dựa trên nội dung thông qua các công cụ khác nhau. Nếu bạn muốn tìm hiểu thêm, hãy xem:
- Twitter tất cả các cặp giống nhau. Chức năng
CosineSimilaritiesScala được thêm vào MLlib có thể được chạy trong môi trường Spark. - Mahout. Nếu bạn muốn truy cập vào nhiều thư viện để bổ sung hoặc thay thế một số thuật toán MLlib, bạn có thể cài đặt Mahout vào thiết lập
bdutil. Bạn có thể thêm Mahout vào thiết lập hiện tại bằng cách nhân bản dự án GitHub:
git clone https://github.com/apache/mahout.git mahout export MAHOUT_HOME=/path/to/mahout export MAHOUT_LOCAL=false #For cluster operation export SPARK_HOME=/path/to/spark export MASTER=spark://hadoop-m:7077 #Found in Spark console
Clustering
Điều quan trọng là phải hiểu bối cảnh duyệt web và những gì người dùng đang xem xét. Cùng một người duyệt web ở những thời điểm khác nhau có thể quan tâm đến hai sản phẩm hoàn toàn khác nhau hoặc thậm chí có thể mua một món quà cho người khác. Có thể hiểu những mặt hàng tương tự như mặt hàng hiện đang trưng bày là cần thiết. Sử dụng cụm K-mean cho phép hệ thống đưa các vật phẩm tương tự vào các thùng dựa trên các thuộc tính cốt lõi của chúng.
Ví dụ, đối với giải pháp này, một người đang tìm kiếm để thuê một ngôi nhà ở London có thể không quan tâm đến việc cho thuê một cái gì đó ở Auckland, do đó, hệ thống nên lọc ra các trường hợp đó khi thực hiện khuyến nghị.
from pyspark.mllib.clustering import KMeans, KMeansModel
clusters = KMeans.train(parsedData, 2,
maxIterations=10,
runs=10,
initializationMode="random")
Chế độ xem 360 độ
Bạn có thể cải thiện đề xuất thêm bằng cách lấy dữ liệu khách hàng khác như các đơn đặt hàng, hỗ trợ và các thuộc tính cá nhân như tuổi tác, vị trí hoặc giới tính. Những thuộc tính này thường có sẵn trong hệ thống quản lý quan hệ khách hàng (CRM) hoặc hệ thống hoạch định nguồn lực doanh nghiệp (ERP) sẽ giúp thu hẹp các lựa chọn.
Suy nghĩ nhiều hơn, không chỉ là dữ liệu hệ thống nội bộ sẽ có tác động đến hành vi và lựa chọn của người dùng; các yếu tố bên ngoài cũng quan trọng. Trong trường hợp cho thuê kỳ nghỉ của giải pháp này, việc có thể biết được chất lượng không khí có thể rất quan trọng đối với một gia đình trẻ. Vì vậy, tích hợp công cụ đề xuất được xây dựng trên Cloud Platform với API khác, chẳng hạn như Breezometer, có thể mang lại lợi thế cạnh tranh.
Tham khảo thêm: Các vị trí tuyển dụng Machine Learning lương cao cho bạn.
Nguồn: topdev.vn via cloud.google.com
- N Ngành nào đang khát nhân lực tại Việt Nam? (2025)
- T Top 10 ngành nghề cho sinh viên mới tốt nghiệp 2025: Bắt đầu từ đâu giữa thời đại chuyển mình?
- L Lộ trình phát triển sự nghiệp cho người muốn đổi ngành
- A Agency và Client trong tổng quan ngành Marketing: Người mới bắt đầu cần hiểu gì?
- M Marketing từ con số 0: Lộ trình chi tiết, rõ ràng cho người mới bắt đầu
- L Làm thêm giờ là tốt hay xấu? Tips OT hiệu quả hơn
- 7 7 vị trí CNTT không cần code giỏi mà vẫn thành công
- B Bức tranh toàn cảnh hệ sinh thái khởi nghiệp công nghệ Việt Nam 2024
- R Reskill là gì? Sự khác nhau giữa Reskill và Upskill
- U Upskill là gì? 5 cách Upskilling bản thân hiệu quả