5 cách mà Deep Learning ảnh hưởng đến cuộc sống của bạn
Bạn có kế hoạch Netflix & Chill cuối tuần này? Thực chất phim bạn chọn sẽ bị ảnh hưởng nhiều bởi thuật toán tinh vi của Netflix. Tương tự, các quyết định nơi bạn chọn đi ăn tối hay những quần áo sẽ mặc đang ngày càng bị ảnh hưởng bởi các công nghệ tiên đoán dựa vào deep learning.
Dưới đây là 5 cách mà các công ty công nghệ phổ biến Netflix, Yelp, Yahoo, Stitch Fix, Google cải thiện trải nghiệm online của bạn với trí tuệ nhân tạo (AI).
Netflix tự động cá nhân hoá Layouts và Movie Thumbnails
Trong lịch sử, xem truyền hình là một kênh truyền thông uni-directional. Bạn xem được nôi dung, nhưng nó không phản hồi lại bất kỳ thông tin gì với nhà sản xuất. Với kĩ thuật số trực tuyến, history của bạn, click chuột và các cụm tự tìm kiếm đều được Netflix ghi nhận để tìm hiểu các lựa chọn của bạn và cung cấp nội dung có liên quan hơn.
Trong năm 2009, Netflix đã trao tặng 1 triệu USD trong cuộc thi mở cho các đội lập trình bên ngoài để cải thiện hệ thống dự báo của công ty. Đội chiến thắng đánh bại thuật toán ban đầu trên 10%.
Kể từ đó, việc giới thiệu các thuật toán machine learning nâng cao hơn giúp cho Netflix đạt được cấp độ mới về dự đoán và cá nhân hoá trên ranking, layout, catalog, new member onboarding, và nhiều hơn nữa. Tony Jebara, Giám đốc của Netflix, Giáo sư khoa học máy tính tại Columbia, giải thích tại hội thảo Deep Learning Summit của REWORK tại San Francisco cách Netflix không chỉ recommend phim tốt hơn, mà còn đưa ra hình ảnh thumbnails tốt hơn cho từng cá nhân.

Theo truyền thống, tối ưu hoá hình ảnh trên trang web ảnh hưởng bởi việc A/B testing hai lựa chọn trong một khoảng thời gian. Vấn đề với phương pháp này là bạn phải đau đớn chờ đợi trước khi có được quyết định tối ưu. Trong giai đoạn này, các đối tượng của bạn sẽ gặp các biến sub-optimal. Tổn thất này của quá trình thử được gọi là “regret”.
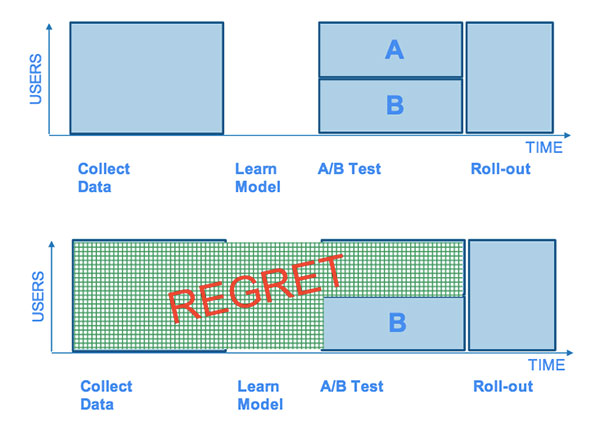
Để giảm thiểu regret, Netflix sử dụng các thử nghiệm như mô hình multi-arm bandit. Các models có thể thay đổi lưu lượng truy cập đến quảng cáo tốt nhất và làm giảm thiểu regret.
Điều quan trọng là sự “tốt hơn” khác nhau đối với mỗi người khác nhau, Netflix sẽ đưa vào tài khoản cá nhân của bạn những hoạt động của bạn để khai thác theo từng cá nhân/ tận dụng khả năng tối ưu. Nếu bạn thường xuyên xem phim hài, họ sẽ sử dụng Robin Williams cho trang bìa của Good Will Hunting. Nếu bạn thích phim tình cảm lãng mạn, họ sẽ dùng ảnh Matt Damon hôn Minnie Driver để thay thế.
YELP hình ảnh đẹp nhất cho bất kỳ địa điểm nào
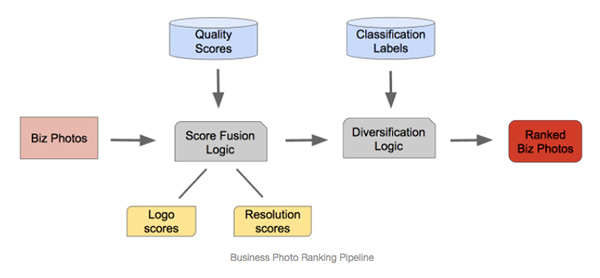
Một bức ảnh đẹp hơn cả ngàn lời nói. Khi bạn đang muốn chọn một chỗ lãng mạn để gây ấn tượng với ngày hẹn hò của mình, bạn sẽ muốn biết về việc sắp đặt món ăn và không khí phù hợp tâm trạng. Để giúp bạn lựa chọn được đúng nhà hàng, Alex Millers và nhóm của mình tại YELP đã dùng thuật toán deep learning để làm nổi bật hình ảnh tốt nhất của người dùng.
Trong khi các số liệu như lượt like và click có thể đánh giá hữu ích các hình ảnh, họ cũng có thể bị ảnh hưởng bởi clickbait và happenstance. Một giải pháp tốt hơn sẽ là đánh giá hình ảnh dựa trên nội dung vốn có và đặc tính – sâu hơn về field, contrast và alignment, nhưng với 25 triệu MAU (monthly active users) tải lên Yelp hàng nghìn bức ảnh mỗi ngày, sẽ không đủ nhân viên để thẩm định.
Tại Startup Machine Learning conference diễn ra tại San Francisco, Miller miêu tả làm thế nào mà team của mình sử dụng CNNs (convolutional neural networks) để xây dựng một model ghi nhận hình ảnh. Một proxy tốt cho hình ảnh đẹp thì có hay không việc chụp bằng DSLR, có thể được nhận ra dễ dàng bằng cách kiểm tra metadata EXIF của hình ảnh.
Team của Miller đã tận dụng fact này để tạo ra khả năng mở rộng, đào tạo bộ dữ liệu bằng cách sử dụng hình ảnh DSLR là một ví dụ tích cực, và không DSLR là một vì dụ tiêu cực. Thuật toán Deep Learning học được những tính chất tốt của hình ảnh từ thiết lập dữ liệu đào tạo và áp dụng cho tất cả các ảnh, cho dù có DSLR hay không.
Bên cạnh chất lượng điểm ảnh, team cũng thêm vào các bộ lọc và đa dạng hoá logic, vì vậy một nhà hàng nổi tiếng với các món ăn hoặc features đặc biệt sẽ không có hình ảnh của họ trong top 10 hình ảnh cùng chủ đề.
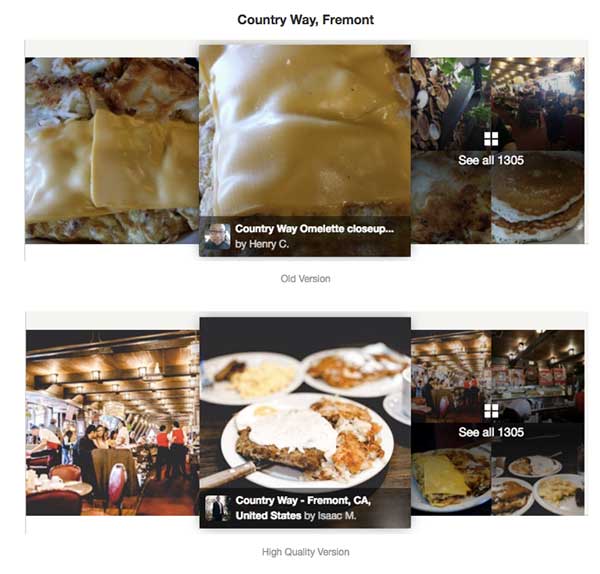
Các kết quả trả về:
Bạn có thể đọc thêm về quy trình kỹ thuật của Miller tại Yelp engineering blog.
YAHOO đảm bảo bạn chọn emoji tốt nhất cho mỗi tình huống
Với các texters lười biếng, emojis là cách dễ nhất để nói ít hiểu nhiều. Nhưng với hơn 1800 emojis, bạn có chắc chắn được một lựa chọn hoàn hảo cho những gì bạn muốn nói không?
Đây là vấn đề của Stacey Svetlichnaya, một nhân viên kĩ thuật machine learning tại YAhoo, phải giải quyết. Khi người dùng soạn hoặc trả lời một tin nhắn, emojis nào nên xuất hiện trong đề xuất tự động? Lý tưởng nhất, bạn có thể chọn 5 emojis thường hay dùng nhất, người dùng có thể chọn.
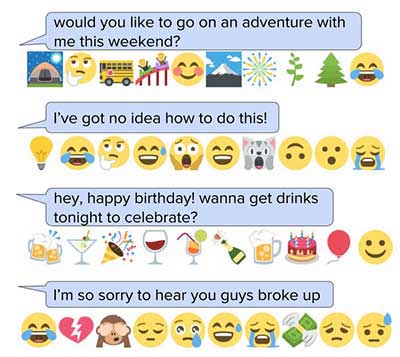
Sử dụng emojis rất năng động. Một số sử dụng để thay thế từ ngữ, một số sử dụng thể hiện cảm xúc, và một văn hoá sử dụng kì lạ. Ví dụ: Emoji con dê thường được sử dụng với ý nghĩa “Vĩ đại nhất mọi thời đại”.
Một thách thức nữa là các biểu tượng khác nhau trên các platforms khác nhau, dẫn đến hiểu nhầm.

Svetlichnaya và Yahoo Vision & Machine Learning team kiểm tra ba cách tiếp cận khác nhau: 1) FastText: một sự phân loại fast linear, 2) LTSM: một loại kiến trúc neural network và 3) WordCNN: một cách tiếp cận net approach cân bằng giữa hiệu xuất và tính phức tạp. Trong 3 cách, không ngạc nhiên với FastText chiến thắng về tốc độ nhưng người ta ưa thích các kết quả của LTSM hơn.
Yahoo không phải công ty duy nhất áp dụng machine learning cho các biểu tượng cảm xúc. Quay lại năm 2015, kỹ sư Instagram đã xuất bản một series hấp dẫn bởi kĩ sư Thomas Dimson gọi là “Emojineering: Machine Learning for emojis”
STITCH FIX nhanh chóng tìm kiếm cho bạn thời trang hoàn hảo
Trở nên fashinable rất khó, nhưng Stitch Fix đã làm nó trở nên dễ dàng. Startup về phong cách cá nhân (personal style) cho phép bạn cá nhân hoá các style profile của bạn và nhận được quần áo và phụ kiện được gửi đến tận nhà hàng tháng.
Xác định phong cách là một khái niệm mơ hồ. Sau tất cả, làm sao bạn có thể nói đến một chiếc áo sơ mi cụ thể là “urban boho chic” hay một chiếc váy là “gợi cảm nhưng không quá slutty”? Christopher Moody có một vài ý tưởng.

Moody là một Data Scientist tại Stitch Fix với background là statistics, astrophysics, và high-performance computing. Hoá ra những kĩ năng này đang làm nhu cầu trong thế giới thời trang.
Nhiều models deep learning là một chiếc hộp đen nơi bạn không hiểu tại sao từ một thuật toán có thể đi đến một kết luận cụ thể. Nghiên cứu của Moody tập trung về việc cải tiến các models để các chuyên gia có thể đưa ra phản hồi về hiệu xuất tương đối của các thuật toán.
Một phương pháp được sử dụng là t-SNE (t-distributed stochastic neighbor embedding), một phương pháp giảm kích thước để giúp hình dung các đối tượng tương tự. Phương pháp giảm kích thước làm giảm flatten dữ liệu thành 2-3 điểm được hiểu dễ dàng hơn.
Moody cũng là một fan hâm mộ lớn của phương pháp k-SVD. k-SVD là một thế hệ của phương pháp k-means clustering. Về high-level non-technical, phân nhóm dữ liệu có tính chất tương tự kết hợp với các đối tượng khác nhau. Một lần nữa, rõ ràng là phân cụm có thể giúp con người có thể xác định được các đặc trưng thống nhất, thêm các thẻ phù hợp như “tank tops” hay “statement pieces”.

GOOGLE DỊCH phương pháp tiếp cận con người
Trong tháng 9 năm 2016, Google Translate công bố họ đã thay thế phương pháp cũ với kiến trúc neural networks. Trước đây, Google Translate sở hữu một phương pháp thống kê gọi là phrase-based machine translation (PBMT)
Phương pháp PBMT thường tạo ra những câu ngữ pháp vụng về, đặc biệt nếu đầu vào và đầu ra khác biệt nhau nhiều trong ngôn ngữ của chúng. Chẳng hạn như Trung Quốc sang tiếng Anh. Để chỉnh sửa cho điều này cần bổ sung kỹ thuật phức tạp và nỗ lực nhiều hơn.

Hệ thống mới GNMT (Google Neural Machine Translation) sử dụng RNNs (recurrent neural networks) ánh xạ toàn bộ câu văn đầu vào của một ngôn ngữ thành một câu văn ở đầu ra của một ngôn ngữ khác. Điều này làm giảm sự phức tạp của các code trong khi vẫn duy trì tốc độ và cải thiện hiệu suất. Trong một số trường hợp như tiếng Pháp sang tiếng Anh, GNMT đã gần như là người dịch (human translation)
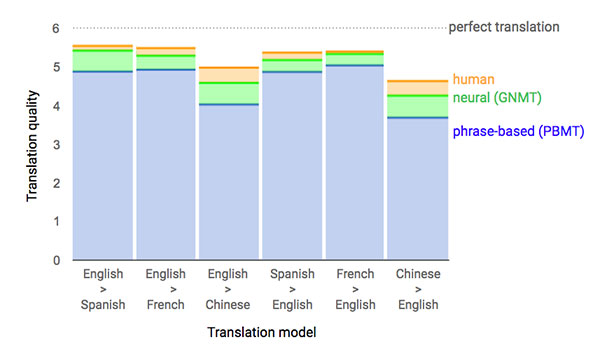
Nếu bạn muốn hiểu sự phát triển kĩ thuật của GNMT và làm thế nào team Google có thể lặp đi lặp lại cải tiến về thiết kế và hiệu suất, đọc Stephen Merity’s visual guide về quá trình này.
Kết luận
Nhiều người tiêu dùng không nhận ra việc trí tuệ nhân tạo cải thiện đáng kể cuộc sống của mình trong các sản phẩm kĩ thuật số. Mô hình thống kê truyền thống dự đoán kinh nghiệm tối ưu được nâng cao đáng kể bởi cách đột phá gần đây trong Big Data, Computational Power, Deep neural networks. Và ngày sẽ có nhiều công ty sử dụng các phương pháp này để tồn tại và cạnh tranh.
Nguồn: topbots.com
- N Ngành nào đang khát nhân lực tại Việt Nam? (2025)
- T Top 10 ngành nghề cho sinh viên mới tốt nghiệp 2025: Bắt đầu từ đâu giữa thời đại chuyển mình?
- L Lộ trình phát triển sự nghiệp cho người muốn đổi ngành
- A Agency và Client trong tổng quan ngành Marketing: Người mới bắt đầu cần hiểu gì?
- M Marketing từ con số 0: Lộ trình chi tiết, rõ ràng cho người mới bắt đầu
- L Làm thêm giờ là tốt hay xấu? Tips OT hiệu quả hơn
- 7 7 vị trí CNTT không cần code giỏi mà vẫn thành công
- B Bức tranh toàn cảnh hệ sinh thái khởi nghiệp công nghệ Việt Nam 2024
- R Reskill là gì? Sự khác nhau giữa Reskill và Upskill
- U Upskill là gì? 5 cách Upskilling bản thân hiệu quả