Tuyệt kỹ: Sử dụng cache để tăng tốc hệ thống
Bài viết của tác giả: Thanh Tú Phạm
Bạn đã bao giờ sử dụng cache để tăng tốc hệ thống?
Nếu dùng redis nó đã cung cấp cho bạn những cấu trúc cơ bản như hash, string, list, set, zset. Tuy nhiên bạn sẽ gặp 2 vấn đề, 1 là invalidate cache ko đơn giản, nhất là phải tính đến việc snapshot rồi replicas, 2 là khi object quá lớn, performance giảm đi nhanh chóng do vấn đề về ram và lạm dụng embeded objects.
Nếu tự tin về cấu trúc dữ liệu và giải thuật + lập trình mạng, bạn có thể build được hệ thống cache phục vụ cho mục đích riêng tối ưu hơn redis nhiều, lưu cả triệu tỉ dữ liệu, strong consistency, và tốc độ cao.
Bài dưới đây giúp bạn build được 1 database lưu 1 cấu trúc dữ liệu json bất kỳ, nhưng cho phép cập nhật được 1 value bất kỳ và truy vấn nó trực tiếp mà không cần phải serialize lẫn deserialize.
Từ đó giúp bạn build được các model dựa trên 1 object khổng lồ mà ko phải bận tâm đến các lệnh join where đau đầu của cơ sở dữ liệu truyền thống. Bởi vì bạn biết rằng, 1 object bất kỳ nó chỉ có 2 kiểu, list và hash, cuối cùng value là primative type mà thôi.
Sử dụng cache để tăng tốc hệ thống
Vấn đề là flattern nó ra, nhờ sự hỗ trợ của cấu trúc tree, tức cơ bản chúng ta cần list, tree và hash là đủ để mô phỏng lại datastructure lưu trong ram, từ đó giải quyết trực tiếp bài toán mà ko cần phải nghĩ đến lưu trữ database, ở dạng tự nhiên nhất.
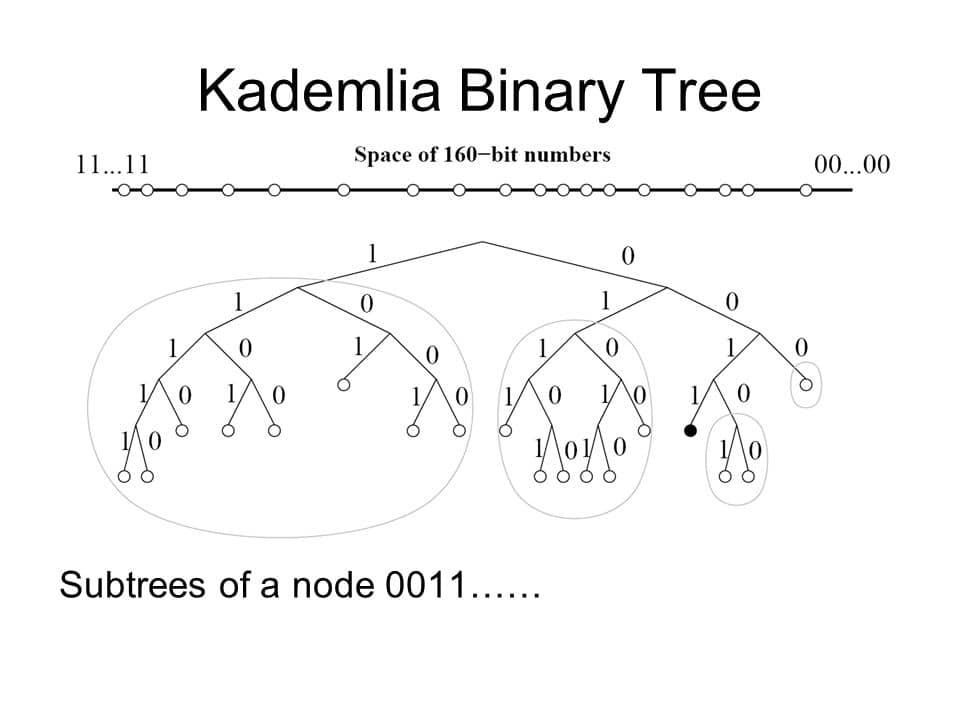 – Xét về lưu trữ trong database, về cơ bản là gồm meta lưu chỉ mục và phần dữ liệu, meta thường là dạng các đoạn bytes chứa chuỗi key và phần còn lại chứa offset value đọc vào file value, nếu key lớn thường padding để chia hết cho 1 chunk size cố định.
– Xét về lưu trữ trong database, về cơ bản là gồm meta lưu chỉ mục và phần dữ liệu, meta thường là dạng các đoạn bytes chứa chuỗi key và phần còn lại chứa offset value đọc vào file value, nếu key lớn thường padding để chia hết cho 1 chunk size cố định.
Xét cơ bản nhất chúng ta cần lưu key-value, key đã được sắp xếp với btree, còn value thuần bytes, với cơ sở dữ liệu quan hệ value có thể gồm các đoạn byte liền nhau theo schema. Lý do ram đọc nhanh vì nó random access theo key từ hash được (bản chất là dùng mảng rồi hash(key) ra index là number), còn trên file phải tìm tuần tự, với btree nó giúp ích rất nhiều rồi.
– Bây giờ chúng ta sẽ ứng dụng 1 db key/value cơ bản như leveldb, về mặt xử lý nó sẽ giống kiểu sắp xếp merge file lớn bằng cách phân tán trên nhiều nodes, rồi chia tiếp trên mỗi node để fit vào ram, ở đây chúng ta sẽ tận dụng cấu trúc key/value trên 1 db duy nhất để build 1 tầng cache rồi sau đó flush cache này vào batch để update database.
Tham khảo thêm các vị trí tuyển dụng web developer lương cao tại Topdev.
2 cách commit để flush cache khi cache đầy
Có 2 cách 1 là chủ động gọi commit để flush cache khi cache đầy, 2 là dùng 1 lru-less recent used để quản lý cache hit, truy cập nhiều thanh ghi nhanh và đưa item ít truy cập ra thanh ghi chậm hơn và xoá hẳn, khi đó cần pre-images hay có thể coi là transaction logs để đẩy vào database, 1 dạng batch có thể get value nếu cache miss và chưa update db.
– Như trên thì việc quản lý cache và lưu trữ khá ổn, nhưng chúng ta ko chỉ lưu mỗi key-value, chúng ta cần lưu thêm các cấu trúc mở rộng khác, hầu hết sẽ là linked list – mô phỏng list trong ram, và tree – mô phỏng 1 json object trong ram.
Lúc này sẽ nẩy sinh vấn đề là conflict key giữa các cấu trúc, và ta sẽ giải quyết đơn giản bằng tính hash của tên object cần lưu + key của nó, sử dụng big.Int. Ví dụ lưu list tên là a, chèn thêm 1 object tên là b, thì key lưu vào sẽ là hash(a) + b. Để lưu được các cấu trúc như list và tree, cơ bản chúng ta cần meta ví dụ list là next key và back key, với tree là left key và right key, parent key, nếu lấy hash 32 bytes làm chuẩn, key length > 32 thì tính hash, chúng ta có thể dùng 64 và 96 byte đầu tiên lưu meta, còn lại là value.
Như vậy không phải serialize gì cả, đọc trực tiếp luôn giống như cơ sở dữ liệu quan hệ vậy, các key/value db hầu hết hỗ trợ đọc offset:limit của value luôn, mặc định nó đọc hết từ meta value của key lấy ra offset limit.
– Phần cuối cùng, đó là phân tán, lẫn strong consistency, về phân tán thì chúng ta sử dụng kademlia routing giống bittorrent, khi lưu batch thì chúng ta broad cast toàn mạng và các node cùng bucket sẽ đồng bộ dữ liệu, cơ bản cài đặt kiểu p2p protocol.
Còn để strong consistency chúng ta có 2 cách, 1 là theo checkpoint giống blockchain, tức block number, đóng gói lại thông tin root key lần gần nhất, và ko được thay đổi, cái này hợp giao dịch vì đã chuyển tiền là ko có sai lệch tài khoản được.
Cách thứ 2 là theo epoch, tức là 1 thời điểm nào đó với 1 duration nào đó sẽ strong consistency, lúc ấy trước khi truy vấn phải lấy về epoch và timeout sẽ ko có dữ liệu, còn pending sẽ đợi, từ đó có thể dựa vào tần suất update để loại những node ít update khi truy vấn latest item.
– Tổng hợp các ý trên bạn có thể build hệ thống cache cực lớn, ăn ít ram nhờ chung 1 db key-value duy nhất, tốc độ cao, và vẫn invalidate cache dễ dàng, nếu dựa vào hash làm reference của object tương tự reference trong bộ nhớ.
Cài đặt Ở đây
- M Martech là gì? Tại sao học ngành marketing nên biết?
- S So sánh chi tiết iOS 18 vs iOS 26: Cuộc cách mạng trên iPhone chỉ sau 1 năm
- B BenQ RD Series – Dòng Màn Hình Lập Trình 4k+ Đầu Tiên Trên Thế Giới
- i iOS 18 có gì mới? Có nên cập nhật iOS 18 cho iPhone của bạn?
- G Gamma AI là gì? Cách tạo slide chuyên nghiệp chỉ trong vài phút
- P Power BI là gì? Vì sao doanh nghiệp nên sử dụng PBI?
- K KICC HCMC x TOPDEV – Bước đệm nâng tầm sự nghiệp cho nhân tài IT Việt Nam
- T Trello là gì? Cách sử dụng Trello để quản lý công việc
- T TOP 10 SỰ KIỆN CÔNG NGHỆ THƯỜNG NIÊN KHÔNG NÊN BỎ LỠ
- T Tìm hiểu Laptop AI – So sánh Laptop AI với Laptop thường