Selenium – Xác Định Đối Tượng UI
Bài viết được sự cho phép của vntesters.com
Trong kiểm thử tự động, phần quan trọng là chúng ta phải làm sao cho công cụ kiểm thử nhận biết và phân biệt được các đối tượng UI trên phần mềm mà chúng ta đang kiểm tra. Trong kiểm thử, chúng ta gọi bước này là xây dựng bộ giao diện người dùng – build GUI Repositories. Cơ bản, nó là một bệ từ điển kết nối giữa một cái tên logic – thứ mà chúng ta dùng trong script – và mô tả vật lý – thứ hiển thị trên phần mềm.
Để có thể tạo một GUI Repository tốt, chúng ta cần xác định mô tả vật lý của đối tượng UI một cách chính xác, đơn nhất và ổn định. Tính chính xác, đơn nhất của mô tả vật lý dùng để đảm bảo script của chúng ta có thể chạy một cách đúng đắn. Tính ổn định giúp chúng ta không phải chỉnh sửa nhiều khi phần mềm có sự thay đổi.
Selenium cũng như vậy, bộ GUI Repository cũng đòi hỏi các tính chất như các công cụ kiểm thử khác. Có khác, chỉ là các thuộc tính của UI là đặc thù về Web mà thôi.
Đối Tượng UI – Locators
Selenium hỗ trợ chúng ta xác định UI dựa trên các thuộc tính, và chúng ta gọi một cách xác định đối tượng UI thông qua thuộc tính của nó là locator, như sau:
- ID
- Name
- Link Text
- CSS Selector
- Tag/ID
- Tag/class
- Tag/attribute
- Tag/class/attribute
- Inner text
- XPath
Đối với ID, đây được coi như là thuộc tính đơn nhất và ổn định nhất của hệ thống phần mềm. Nếu có thể sử dụng ID cho việc xác định UI thì quá tốt. Nhưng, tất cả chúng ta đều biết, hiếm có một nhà phát triển phần mềm nào lại chăm chỉ đến mức gắn ID cho mọi đối tượng UI. Đơn giản là vì ID không phải là một thuộc tính bắt buộc và nó không hiện thị trên giao diện nên bên viết ra phần mềm không chú ý đến nó cũng là hiển nhiên.
Về phần Name. Name là lựa chọn thứ hai sau ID. Tuy nhiên, thuộc tính Name đôi khi không đơn nhất. Không có một ràng buộc nào bắt Name phải đơn nhất cả. Xin lỗi, mình ngoài lề một chút, đối với ID, cũng sẽ không có lỗi systax nào xảy ra nếu nhà phát triển đặt hai đối tượng UI cùng ID, nhưng nó là một bug về ý nghĩa. Nếu bạn làm Unit Test, bạn có thể bắt bug này.
Link Text. Một lựa chọn không tồi nếu bạn không phải kiểm định trên hệ thống với nhiều ngôn ngữ khác nhau. Thuộc tính Link Text là không đơn nhất và cũng không ổn định. Một trang web có thể có nhiều liên kết đến một trang khác hay thay đổi từ ngữ nhưng không đổi ý nghĩa. Thử tưởng tượng, một ngày nào đó, nút Login của chúng ta bị chuyển thành SignIn. Wow….
CSS Selector. Sử dụng CSS là chúng ta phụ thuộc vào cách thiết kế web của nhà phát triển. Và hiển nhiên, CSS Selector không đơn nhất. Không một nhà phát triển nào tạo ra một CSS để dùng cho một đối tượng cả. Cho nên, chúng ta phải kết hợp CSS với Tag/ID, Tag/class, ….
Cuối cùng, XPath. Đây được xem như là thuộc tính hay dùng nhất của Selenium. Tuy nhiên, cách này lại thiếu chính xác, thiếu đơn nhất và thiếu ổn định nhất trong tất cả các cách xác định đối tượng UI.
Xác định đối tượng UI với Selenium IDE
Trong Selenium IDE, khi chúng ta record một test case, IDE đã tự động xác định đối tượng UI cho chúng ta. Nhưng, đôi khi các thuộc tính do IDE lấy ra không thể sử dụng được. Các bạn có thể thử với Google, ở đó có hai đối tượng UI có cùng ID.
Để xác định một đối tượng UI với Selenium IDE, chúng ta làm như sau:
B1: Mở trang web mà chúng ta đang muốn kiểm tra
B2: Mở Selenium IDE
B3: Gõ locator của đối tượng mà chúng ta muốn xác định vào Target textbox. Cấu trúc và ví dụ cho các locators mình liệt kê ở cuối bài.
B4: Click Find button
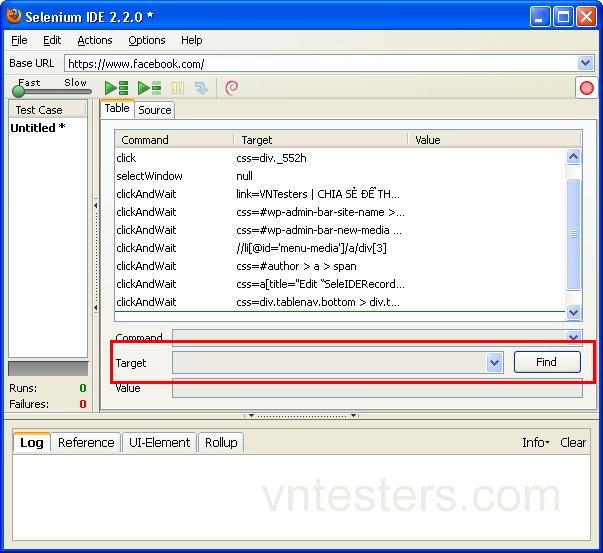
Nếu các locator của đối tượng mà chúng ta điền vào Target là đúng, đối tượng UI sẽ được sáng nhấp nháy trên trang web.
Và đây là cách chúng ta tạo ra các locator với từng phương thức khác nhau:
|
Phương thức |
Cấu trúc |
Ví dụ |
|
ID |
id= id_của_đối_tượng |
id=email |
|
Name |
name=name_của_đối_tượng |
name=username |
|
Name |
name=name_của_đối_tượng |
name=tripType |
|
Link Text |
link=link_text |
link=REGISTER |
|
Tag/ID |
css=tag#id |
css=input#email |
|
Tag/Class |
css=tag.class |
css=input.inputtext |
|
Tag/Attribute |
css=tag[attribute=giá trị] |
css=input[name=lastName] |
|
Tag/Class/Attribute |
css=tag.class[attribute=giá trị] |
css=input.inputtext[tabindex=1] |
|
XPath |
Xpath |
//html/body//bookstore/book/title |
Để có thể xác định được locator một cách nhanh chóng và chính xác hơn, các bạn có thể sử dụng hai công cụ khá mạnh của FireFox: FireBug và XPath Finder. FireBug hỗ trợ chúng ta đọc mã nguồn của trang web một cách rõ ràng, và XPath Finder giúp chúng ta lấy XPath của đối tượng UI một cách chính xác và đơn giản.
Bài viết gốc được đăng tải tại vntesters.com
Có thể bạn quan tâm:
- M Martech là gì? Tại sao học ngành marketing nên biết?
- S So sánh chi tiết iOS 18 vs iOS 26: Cuộc cách mạng trên iPhone chỉ sau 1 năm
- B BenQ RD Series – Dòng Màn Hình Lập Trình 4k+ Đầu Tiên Trên Thế Giới
- i iOS 18 có gì mới? Có nên cập nhật iOS 18 cho iPhone của bạn?
- G Gamma AI là gì? Cách tạo slide chuyên nghiệp chỉ trong vài phút
- P Power BI là gì? Vì sao doanh nghiệp nên sử dụng PBI?
- K KICC HCMC x TOPDEV – Bước đệm nâng tầm sự nghiệp cho nhân tài IT Việt Nam
- T Trello là gì? Cách sử dụng Trello để quản lý công việc
- T TOP 10 SỰ KIỆN CÔNG NGHỆ THƯỜNG NIÊN KHÔNG NÊN BỎ LỠ
- T Tìm hiểu Laptop AI – So sánh Laptop AI với Laptop thường