Sao lưu và đồng bộ dữ liệu – Redundancy and Replication
Bài viết được sự cho phép của tác giả Edward Thiên Hoàng
REDUNDANCY
Là phương thức sao lưu các dữ liệu quan trọng của hệ thống với mục đích tăng độ tin cậy (Reliability) của hệ thống. Ví dụ dữ liệu được lưu trên duy nhất một Server, nếu Server đó mất có nghĩa là tất cả dữ liệu đó mất, do đó việc tạo ra các bản sao lưu là để giải quyết vấn đề này. Redundancy là một điều kiện để xóa bỏ những “single points of failure” và tạo ra các bản sao lưu lúc cần thiết, ví dụ ta có hai máy chủ Database đang chạy trên production và dữ liệu luôn được sao lưu đồng bộ giữa hai máy chủ, và nếu có một trong hai máy chủ bị down thì ta có thể failover sang máy chủ còn lại. Redundancy nó giống như duplicate lại node/server dùng cho mục đích back-up vậy.
REPLICATION
Gần tương tự với với Redundancy là ta cũng tạo ra một bản sao lưu dữ liệu của Server chính (Master) sang Server backup (Slave), nhưng khác nhau cơ bản là Replication sẽ update dữ liệu giữa Master và Slave là luôn luôn giống nhau và mọi thời điểm (real time synchronization) để tăng độ tin cậy (reliability), đặc biệt là khả năng chịu lỗi của hệ thống (fault-tolerance) và khả năng truy cập (accessibility). Replication được sử dụng rộng rãi ở các CSDLQH (RDBMS) trong mô hình master/slave, dữ liệu giữa master-slave luôn luôn được đồng bộ, trong trường hợp master down thì slave sẽ lên thay master sau khi master vừa down sống dậy nó sẽ trở thành slave mà sẽ thực hiện đồng bộ dữ liệu chưa được update trong thời gian nó bị down.
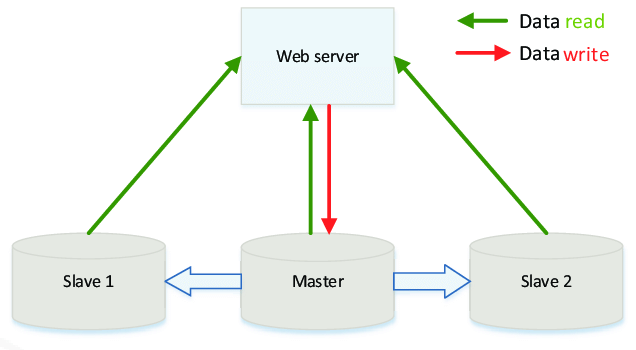
Mô hình Master — Slave
Theo medium
Bài viết gốc được đăng tải tại edwardthienhoang.wordpress.com
Có thể bạn quan tâm:
Xem thêm Việc làm Developer hấp dẫn trên TopDev
- B BenQ RD Series – Dòng Màn Hình Lập Trình 4k+ Đầu Tiên Trên Thế Giới
- i iOS 18 có gì mới? Có nên cập nhật iOS 18 cho iPhone của bạn?
- G Gamma AI là gì? Cách tạo slide chuyên nghiệp chỉ trong vài phút
- P Power BI là gì? Vì sao doanh nghiệp nên sử dụng PBI?
- K KICC HCMC x TOPDEV – Bước đệm nâng tầm sự nghiệp cho nhân tài IT Việt Nam
- T Trello là gì? Cách sử dụng Trello để quản lý công việc
- T TOP 10 SỰ KIỆN CÔNG NGHỆ THƯỜNG NIÊN KHÔNG NÊN BỎ LỠ
- T Tìm hiểu Laptop AI – So sánh Laptop AI với Laptop thường
- M MySQL vs MS SQL Server: Phân biệt hai RDBMS phổ biến nhất
- S SearchGPT là gì? Công cụ tìm kiếm mới có thể đánh bại Google?