Mechanical Sympathy Là Gì? Lập Trình BackEnd bằng Java
Bài viết được sự cho phép của tác giả Trần Văn Dem
Khi lập trình backend bằng ngôn ngữ Java, nếu muốn chương trình chạy nhanh hơn chúng ta sẽ sử dụng khái niệm multithreading để tăng hiệu năng tổng thể của chương trình. Tuy nhiên khi sử dụng multithreading cũng sẽ gây ra các sai lầm về mặt dữ liệu nên chúng ta sẽ sử dụng các kỹ thuật như lock , synchronized để đảm bảo việc đó. Nhưng sử dụng các cơ chế này sẽ gây giảm hiệu năng chương trình của bạn xuống.
Các CPU hiện nay hỗ trợ rất tốt cho lập trình đa luồng nhưng hiểu rõ cách hoạt động của CPU sẽ giúp chương trình của bạn sẽ nhanh và chính xác hơn. Việc hiểu cách hoạt động của CPU để viết phần mềm tận dụng hết khả năng của phần cứng được biết đến với tên mechanical-sympathy. Bài này sẽ giúp mọi người hiểu rõ hơn về CPU, cách lập trình đa luồng tốt hơn.
Cách CPU xử lý dữ liệu
Sau đây là kiến trúc cơ bản của một CPU
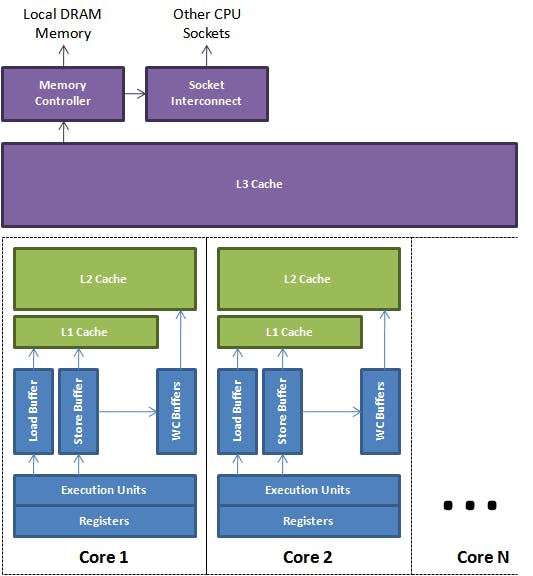
Tại đây chúng ta thấy một CPU sẽ sử dụng chung một bộ nhớ cache L3. Các bộ nhớ L1,L2 sẽ là của riêng các core trong cpu. Tốc độ cpu truy cập các bộ nhớ L1,L2,L3 sẽ giảm dần và độ lớn của bộ nhớ cache L1,L2,L3 sẽ tăng dần. CPU sẽ không Load dữ liệu trực tiếp từ RAM để xử lý vì hành động này sẽ rất tốn thời gian. Khi cần thao tác với 1 biến thì CPU sẽ tìm tại bộ nhớ L1, L2, L3 nếu không có thì mới load từ RAM vào các bộ nhớ cache trên.
CPU sẽ không load dữ liệu cơ bản mà sẽ load theo dạng Cache line. Cache line này thường sẽ là 64b
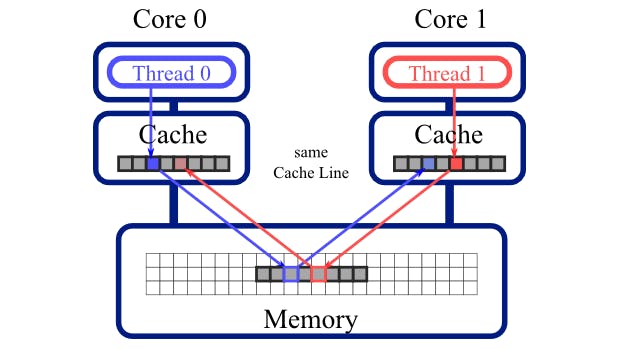
Lý do CPU load dữ liệu theo Cache line bởi vì nó có thể tận dụng được 1 lần load được nhiều dữ liệu hơn và nếu các phép tính toán cần sử dụng các loại dữ liệu này thì sẽ không được load lại.
Ví dụ khi chúng ta duyệt giá trị trong 1 Array thì các phần tử Array sẽ được xếp cạnh nhau trong memory nên khi load vào để tính toán sẽ được load theo Cache line điều đó sẽ tăng performance của CPU. Với Java khi chúng ta khai báo biến nguyên thủy trong 1 Object thì các biến đó sẽ được xếp cạnh nhau trên RAM, với các biến Object thì chỉ chứa Reference chứ nội dung của nó sẽ được lưu ở chỗ khác tại memory*.
Xem tin tuyển dụng Java mới nhất trên TopDev
False Sharing
Nếu 2 biến X,Y cùng nằm trên 1 Cache line , Thread 0 sử dụng và thay đổi giá trị của biến X và xảy ra trước khi Thread 1 sử dụng biến Y. Điều này sẽ khiến Cache line bị CPU sẽ đánh dấu là Invalid và điều đó sẽ khiến Core 2 bắt buộc phải Load lại Cache line trước khi sử dụng biến Y. Điều trên được gọi là False Sharing.
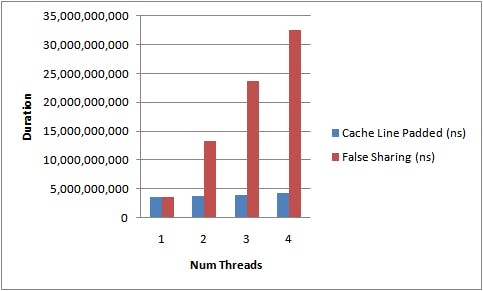
False Sharing thực sự sẽ ảnh hưởng đến hiệu suất chương trình của bạn vì nó khiến Core load lại CacheLine nhiều lần điều đó sẽ càng phức tạp nếu nhiều hơn 2 luồng và mỗi luồng sẽ lại thay đổi 1 biến trên cache line. Vậy nên trước khi tăng tài nguyên thì hãy chắc chắn rằng chương trình bạn viết không bị False Sharing. Các bộ profile của intel sẽ cho bạn biết chương trình có đang bị False Sharing hay không nhưng có 1 cách đơn giản hơn khi lập trình MultiThread là hãy cố thiết kế hệ thống sao cho các Thread của bạn không sử dụng chung các object. Mỗi luồng sẽ có 1 bộ dữ liệu riêng để truy cập thay vì chia sẻ chung 1 Array, Map, Object,…
Tham khảo tại link dưới dây để đo hiệu năng khi chương trình bị False Sharing :
- mechanical-sympathy.blogspot.com/2011/07/fa..
- mechanical-sympathy.blogspot.com/2011/08/fa..
Race condition
Khái niệm race condition thì chắc hẳn ai code multi threading cũng biết và biết các cách chống lại điều này. Nhưng chắc cũng không ít anh em đọc đến False Sharing sẽ thấy lú là sao đã có False Sharing rồi nhưng lại có thể race condition được. Các CPU của intel, amd sẽ có 1 giao thức để thực hiện invalid cacheline. MESI Protocol tham khảo tại:
- cs.utexas.edu/~pingali/CS377P/2018sp/lectur…
- people.cs.pitt.edu/~melhem/courses/2410p/ch..
Protocol này được mô tả rất kỹ trong 2 link trên hoặc mọi người hãy search google để tìm đọc thêm về protocol này. Tóm tắt lại Protocol này sẽ đánh dấu cache line có 4 state sau :
- Invalid (uncached)
- Shared
- Exclusive
- Modified
Đây là mô tả chương trình của chúng ta khi bị race condition
CYCLE # CORE 1 CORE 2
0 reg = load(&counter);
1 reg = reg + 1; reg = load(&counter);
2 store(&counter, reg); reg = reg + 1;
3 store(&counter, reg);
0 reg = load(&counter);
CORE1 load counter vào bộ nhớ cache. Đánh dấu Cacheline là Exclusive
1 reg = reg + 1; reg = load(&counter);
CORE1 tăng biến reg. CORE2 load biến counter vào cache. Tại thời điểm này cả 2 Cacheline là Shared
2 store(&counter, reg); reg = reg + 1;
CORE1 lưu giá trị mới cho biến counter. CORE2 thực hiện tính toán. Tại thời điểm này CORE1 đánh dấu cache line là Modified, ngay sau đó CORE 2 sẽ nhận được cacheline đã bị thay đổi và đánh dấu cho Cache line là Invalid.
3 store(&counter, reg); Vì Cache line đã bị invalid nên CORE2 thực hiện load lại biến counter trước khi thực hiện hành động store. Và biến counter đã được CORE1 lưu lại trước đó nên tại đây CORE2 sẽ thực hiện lưu lại giá trị của CORE1 đã lưu.
Sau cùng cacheline của CORE1 sẽ là Invalid và CORE2 sẽ là Modified. Vì CORE1 đã thực hiện xong hành động nên khi được mark là Invalid lần tính toán sau CORE1 sẽ load lại cacheline này.
Vậy khi sảy ra trường hợp race condition chương trình chúng ta sẽ đưa ra một kết quả sai và tệ hơn nữa nó lại gây cho CORE thực hiện load lại nhiều lần cacheline vào trong bộ nhớ cache của mình.
Happens-before relationship Java
Trong Lập trình đa luồng của Java cung cấp cho chúng ta khái niệm happens-before relationship.
Trước khi tìm hiểu Happens-before relationship ta sẽ tìm hiểu về cách CPU thực hiện Instruction Reordering.
Các CPU hiện nay có khả năng sắp xếp thứ tự thực hiện các instruction để có thể thực thi chúng song song(parallel).
Ví dụ:
a = b + c
d = a + e
l = m + n
y = x + z
Sau khi CPU thực hiện Instruction Reordering
a = b + c
l = m + n
y = x + z
d = a + e
Với các instruction trên được sắp xếp lại, CPU có thể thực hiện 3 instruction đầu tiên song song vì chúng không phụ thuộc lẫn nhau trước khi thực thi instruction thứ 4 -> tăng performance.
Tuy nhiên trong vài trường hợp khi thực hiện thì Instruction Reordering sẽ dẫn đến việc chương trình thực hiện không đúng trên nhiều luồng như ví dụ sau đây:
Thread1
(1) this.balance += 10000;
(2) this.isDepositSuccess = true;
Thread2
(3) if (this.isDepositSuccess) {
(4) getBalance();
}
Nếu CPU sắp xếp lại thứ tự thực hiện instruction (2) trước (1) thì ở Thread2 có thể xảy ra trường hợp điều kiện (3) đúng nhưng giá trị balance chưa được update -> chương trình sẽ không hoạt động đúng, vẫn lấy ra giá trị balance cũ. Ở đây Happens-before relationship sẽ giải quyết vấn đề đó, nó đảm bảo thứ tự thực hiện được giữ nguyên. Tất cả thay đổi xảy ra ở Thread1 trước khi ghi isDepositSuccess sẽ được nhìn thấy và cập nhật ở Thread2 khi đọc isDepositSuccess.
Trong Java, Happens-before relationship được đảm bảo khi sử dụng volatite, synchronized và java.util.concurrent.atomic.
Tham khảo link này về cách volatite, synchronized đảm bảo Happens-before relationship.
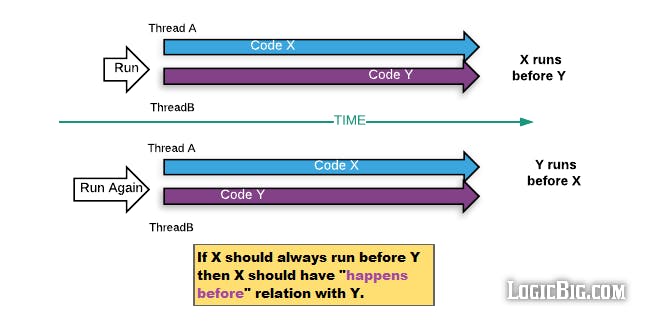
Nếu hành động X, Y được thực hiện trên 2 luồng khác nhau nhưng hành động X xảy ra trước khi hành động Y thì mọi thay đổi của X sẽ được luồng thực hiện hành động Y nhìn thấy và cập nhật. Theo cơ chế này chúng ta không cần nhất thiết phải sử dụng lock, synchronized để chia sẻ dữ liệu giữa các luồng chỉ cần đảm bảo một một quan hệ Happens-before-relationship thì dữ liệu sẽ được đồng bộ(sử dụng volatile trong trường hợp chỉ có duy nhất 1 luồng ghi).
Trong trường hợp có nhiều hơn 1 luồng sửa đổi dữ liệu chúng ta sẽ sử dụng các cơ chế lock, synchronized . Trong Java thì các hoạt động này cũng sẽ là happens-before relationship.
Concurrent is hard and lock is bad
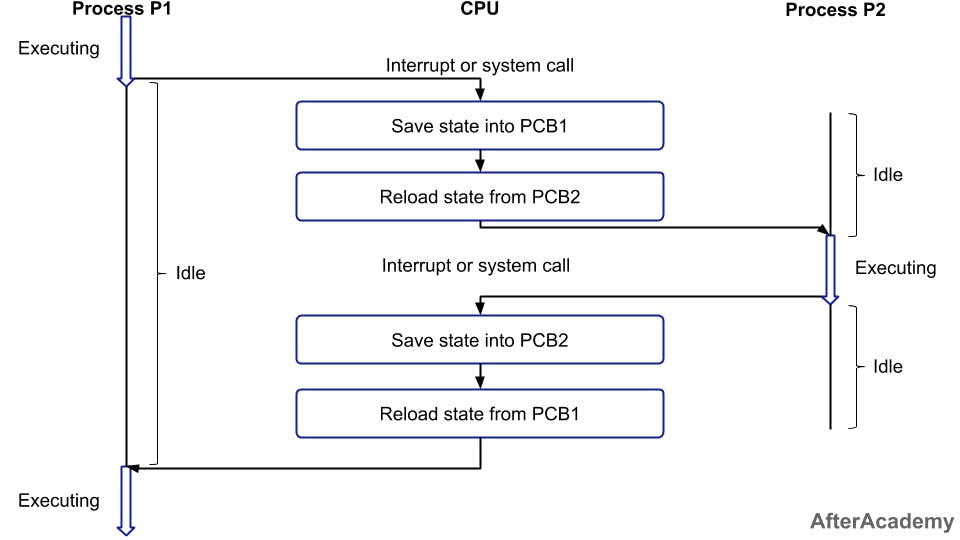
Lập trình đa luồng là rất khó đối với tất cả developer để tránh race condition chúng ta thường sử dụng cơ chế lock. Đây là một cách dễ dàng nhất nhưng nó lại mang lại hiệu năng thấp nhất.
Lý do lock mang lại hiệu năng thấp hơn các thuật toán chia sẻ tài nguyên khác là khi sử dụng lock sẽ gây lên context switching trong CPU.
Khi CPU chuyển từ thực hiện logic của luồng hiện tại sang thực hiện logic của luồng khác, CPU cần phải lưu lại dữ liệu cục bộ, trạng thái,… của luồng hiện tại và load dữ liệu, con trỏ,… của luồng khác để thực hiện logic. Quá trình chuyển đổi này được gọi là context switching, quá trình này thực sự không hề rẻ nên bạn cần tìm cách tránh nó khi lập trình.
Bạn có thể thay thế bằng cách sử dụng cơ chế CAS trong Java đại diện là các lớp Atomic. Trên thực tế cũng có các thuật toán lock free xây dựng trên cơ chế CAS khi sử dụng các thuật toán này mọi người lưu ý code tránh bị trường hợp False Sharing. Có một thư viện xây dựng queue rất nổi tiếng dựa trên cơ chế CAS có hiệu năng cực cao trên Java là LMAX Disruptor. Nếu bạn đọc được code Java bạn nên đọc qua mã nguồn của thư viện này. Sau khi hiểu được cơ chế cũng như cách hoạt động của LMAX Disruptor thì khẳng định bạn sẽ dùng nó để tăng chương trình Multithreading của mình.
Kết Luận
Khi lập trình concurrency chúng ta cần cố gắng thiết kế các luồng đọc các dữ liệu khác nhau, hạn chế sử dụng lock vì sẽ gây context switching ảnh hưởng đến hiệu năng của hệ thống. Nếu làm được như vậy thì hệ thống của bạn đã làm theo một khái niệm mechanical-sympathy phần cứng sẽ giúp chương trình của bạn chạy nhanh nhất có thể. Lập trình concurrency là rất khó và để lập trình concurrency hiệu quả nhất thì lại càng khó hy vọng sau bài viết này các bạn sẽ có những keyword để phục vụ trong quá trình làm việc.
Bài viết gốc được đăng tải tại demtv.hashnode.dev
Bài viết liên quan:
- Lập trình đa luồng trong Java (Java Multi-threading)
- Đồng thời (Concurrency) và song song (Parallelism) khác nhau như thế nào?
- Top 5 câu hỏi phỏng vấn java hay nhất
Đừng bỏ lỡ hàng loạt việc làm IT hấp dẫn trên TopDev nhé!
- V Vì sao lập trình viên BE cần phải biết Figma?
- N Nên học Front-end hay Back-end trước?
- H Học back end cần học những gì? Lộ trình cho người mới bắt đầu
- T Tầm quan trọng của Loose Coupling trong hệ thống Backend
- L Lập trình Web nên học ngôn ngữ nào là phù hợp?
- N Nên học Front-end hay Back-end? Sự khác biệt là gì?
- P Phân biệt Front End và Back End, điểm khác nhau là gì?
- T Top 7 câu hỏi phỏng vấn Backend Developer
- L Lộ trình học MySQL từ A đến Z
- Q Quản lý realm database theo hướng micro-service trong iOS