Giới thiệu nền tảng máy học ML.NET của Microsoft
Bài viết được sự cho phép của tác giả Trần Duy Thanh
ML.NET là gì?
ML.NET là thư viện máy học Mã nguồn mở và chạy cross-platform (Windows, Linux, macOS) của Microsoft. Ta có thể lập trình được thư viện này trên các nền tảng như Desktop, Web, hay build các Service. Nó được đánh giá là mạnh mẽ có thể làm được những gì một số thư viện khác làm được (chẳng hạn như scikit-learn viết bằng Python) và làm được những thứ mà thư viện khác không làm được.
Với việc sở hữu các nền tảng công nghệ mạnh mẽ nhất, khách hàng sẵn có trải rộng khắp thế giới nên ML.NET được kỳ vọng rất lớn sẽ tạo ra được cơn sốt về công nghệ liên quan tới máy học viết bằng C#/F# và tạo ra thị trường lao động ở phân khúc này là rất khả thi.
Theo thông tin từ hãng thì ML.NET bắt đầu khởi động từ 05/2018 và hiện nay bản chạy ổn định là 1.7.0 (tính tới 02/2022), và Microsoft cùng cộng đồng đang tiếp tục bổ sung tính năng cũng như cải tiến hiệu suất của các giải thuật.
Linh hồn của ML.NET là một mô hình học máy (machine learning model). Mô hình này chỉ định các bước cần thiết để chuyển đổi dữ liệu đầu vào của ta thành các kết quả dự đoán của mô hình, nó tùy vào giải thuật mà chúng ta lựa chọn. Với ML.NET, Ta có thể tùy chỉnh mô hình bằng cách lựa chọn các thuật toán machine learning của ML.NET (dĩ nhiên nó phải lệ thuộc vào bài toán ta muốn làm là gì để chọn giải thuật cho phù hợp) hoặc ta cũng có thể import các mô hình của TensorFlow hay ONNX đã được đào tạo trước để sử dụng. Ngoài ra ML.NET cũng cung cấp hàm cho ta lưu mô hình để tái sử dụng cũng như chia sẻ model cho cộng đồng.
Xem ngay tin tuyển dụng lập trình viên .NET tại các doanh nghiệp hàng đầu trên TopDev
Về cơ bản thì 1 bài toán Machine learning nó sẽ hoạt động như hình dưới đây (hình nguồn Microsoft):
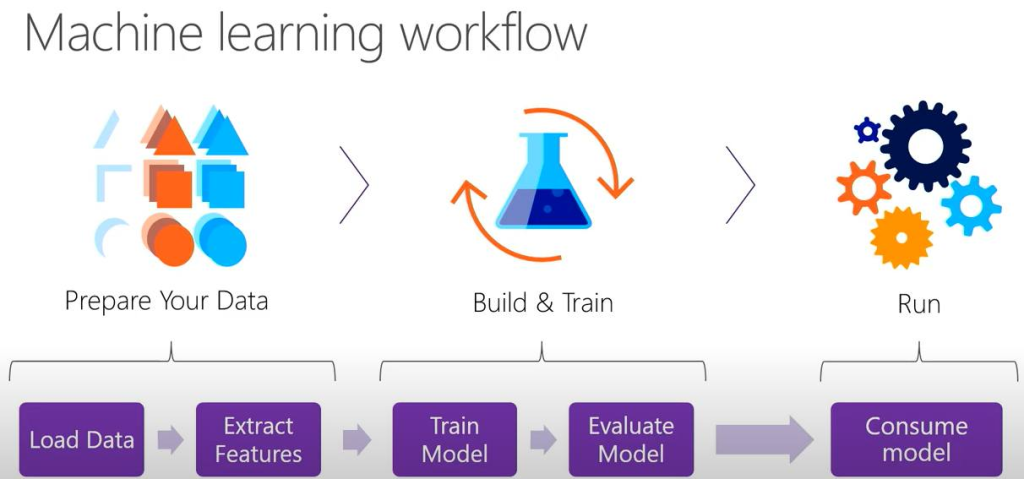
Đại khái tui tóm tắt các bước trong 1 bài toán Machine learning như sau (dĩ nhiên tùy vào kỹ thuật, kinh nghiệm của mỗi người mà ta tiến hành các bước cho riêng mình, ở đây Tui nói tổng quan):
- Bước 1: Chuẩn bị dữ liệu, bước này cần chuẩn hóa dữ liệu do thường ban đầu các dữ liệu nó bị “ô nhiễm” tức là nó chứa các dữ liệu không đúng, dữ liệu chứa rác không đáp ứng được nhu cầu. Ví dụ như nếu dữ liệu text thì có các ký tự viết tắt, ký tự lạ, biểu tượng… Dữ liệu hình thì có các hình mờ không thể nhận dạng, dữ liệu Video thì có Video bị lỗi.
- Bước 2: Rút trích đặt trưng, cứ hiểu là bước vector hóa dữ liệu, các dữ liệu thường được mã hóa về các ma trận dạng số, bước này giờ đã dễ dàng hơn, ta chỉ cần nạp cấu trúc đối tượng và truyền các mảng thuộc tính tương ứng, ML.NET sẽ làm giúp ta điều này. Ở bước này đôi khi sẽ được làm đồng thời với việc chia dữ liệu ra làm 2 phần: Train set và Test set. Và nó tùy thuộc vào tỉ lệ lấy dữ liệu thì mô hình chạy có thể cho ra chất lượng khác nhau. Các bạn tưởng tượng có 100 đề thi thì 100 đề này là dữ liệu, nếu lấy 80 đề thi ra để luyện tập (nó gọi là Train Set), sau khi luyện tập xong ta lấy 20 đề kia ra để làm xem được hay không (20 đề đó gọi là Test set). Trong máy học có thêm khái niệm về Over-fit, nếu bạn lấy 100 đề đó ra luyện tập, sau đó lại lấy 1 đề trong 100 đề đó ra để làm bài test, thì lúc này đa phần bạn làm điểm cao nhưng mà điểm cao trong tự sướng (Over fit vì bạn tưởng nhầm là mình đã được train giỏi, nhưng là do bạn đã làm trước đó rồi, dẫn tới khi đi thi thực tế ra 1 đề lạ hoắc có thể bạn sẽ bị rớt.
- Bước 3: Tiến hành Build/Train mô hình: Tùy vào bài toán phân lớp, gom cụm… thì ta sẽ dùng các giải thuật khác nhau để build mô hình. Ví dụ như có 1 dữ liệu Comment của khách hàng, hỏi xem comment này là tích cực hay tiêu cực thì nó thuộc bài toán phân lớp, như vậy ta sẽ dùng các giải thuật phân lớp. Hay nếu có một tập dữ liệu các căn nhà và giá của nó, giờ muốn dự báo xem 1 căn nhà bất kỳ có giá bao nhiêu thì nó lại thuộc bài toán hồi quy. Bước 3 sẽ chọn đúng giải thuật để build mô hình cho đúng
- Bước 4: Đánh giá mô hình, mọi mô hình được build xong cần được đánh giá nó xem chất lượng của nó tới đâu (không có mô hình đúng hay sai chỉ có mô hình chất lượng hay không), và chất lượng hay không nó lệ thuộc vào các thang đo, ví dụ như trong các bài hồi quy thì nó các thang đo R-Squared, MSE, RMSE, MAE, và hầu như các giải thật cũng có Loss Function. R-Squared càng cao (tịnh tiến tới 100%) thì mô hình càng tốt, (dĩ nhiên với các bài về chứng khoán thì chưa chắc do nó nhảy múa, thông thường R-Squared >=50% là ổn, nhưng không có nghĩa là <50% là tệ), còn MSE, RMSE, MAE, Loss function thì thấp sẽ càng tốt. Việc quyết định chọn mô hình nào là tùy thuộc vào kinh nghiệm của người build mô hình và có tham khảo các độ đo này. Và lưu ý là ứng với mỗi loại giải thuật máy học thì độ đo sử dụng sẽ khác nhau, Tui chỉ ví dụ về giải thuật hồi quy để các bạn hiểu sơ lược vậy
- Bước 5: Sử dụng mô hình, ở bước này thường là sau khi bước 4 đánh giá xong, thì ta sẽ lưu mô hình xuống ổ cứng và có thể chia sẻ lên cloud, lưu lại để lần sau chỉ lấy ra sài thôi, không phải tốn công chạy lại (tiết kiệm thời gian và chi phí), khi khi lưu xong muốn sài thì load mô hình lên để sài. Còn sài như thế nào nó tùy thuộc vào bài toán của mình để gọi hàm Predict cho phù hợp.
ML.NET hỗ trợ các bài toán nào liên quan tới Máy Học?
- Classification: Ví dụ các bài toán về phân loại cảm xúc khách hàng tích cực hay tiêu cực từ các feedback của họ
- Clustering : Ví dụ các bài toán về gom cụm khách hàng, giả sử có N khách hàng ta cần phải gom thành k cụm, các cụm này chứa các đặc trưng khác nhau của khách hàng.
- Regression/Predict continuous values: Ví dụ các bài toán về hồi quy như dự đoán giá nhà, giá taxi …. từ một tập dữ liệu giao dịch trong quá khứ, hãy dự đoán giá của nó là gì khi có một số dự kiện mới.
- Anomaly Detection: Các bài toán về phát hiện bất thường, chẳng hạn như Phát hiện các giao dịch gian lận trong ngân hàng
- Recommendations: Các bài toán về khuyến nghị, ví dụ như làm sao quảng cáo được sản phẩm tới đúng khách hàng có nhu cầu, làm sao khi vào tiki thì nó gợi ý được các cuốn sách mà người này quan tâm.
- Time series/sequential data: các bài toán như dự báo thời tiết hay doanh số bán sản phẩm
- Image classification: các bài toán về phân loại hình ảnh
- Object detection: Các bài toán về Phát hiện đối tượng
Dưới đây là hình minh họa sự khác biệt giữa Image classification và Object detection (hình nguồn Microsoft)

Cơ chế hoạt động của ML.NET như thế nào?
Ở trên Tui đã nói các bước hoạt động chung của một phần mềm liên quan máy học rồi, còn với ML.NET, khi sử dụng các thư viện của Microsoft thì cơ chế hoạt động như thế nào? về cơ bản là nó đúng với các bước cơ bản chung, Tui có vẽ lại workflow mà Microsoft cung cấp (hình gốc Tui thấy mờ và không đẹp nên Tui đã vẽ lại cho rõ và đẹp hơn).
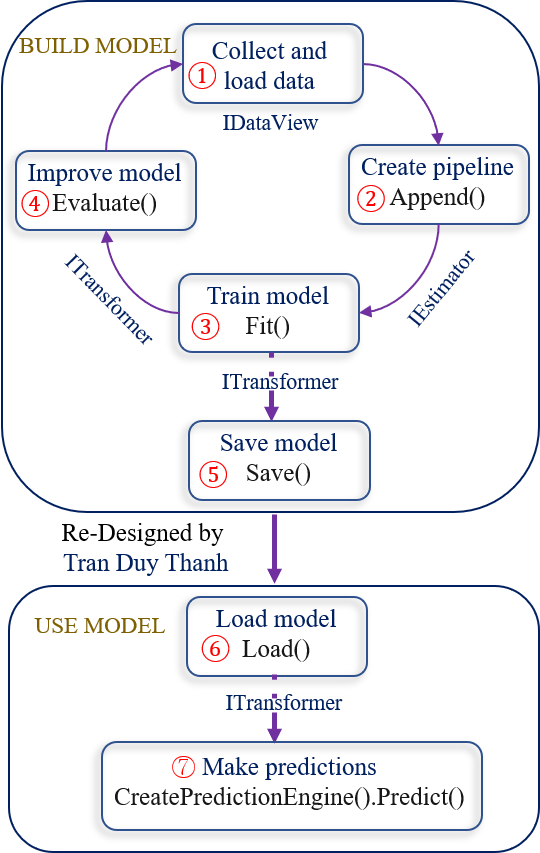
Ở hình trên như các bạn thấy thì sẽ có 7 bước hoàn chỉnh trong quá trình sử dụng thư viện máy học ML.NET của Microsoft. Tui tóm tắt lại như dưới đây (các coding chi tiết Tui sẽ trình bày ở các bài sắp tới):
- Bước 1: là bước chuẩn bị dữ liệu, ở bước này tùy vào bài toán mà ta thu thập dữ liệu khác nhau, dữ liệu sau khi thu thập phải được làm sạch/ chuẩn hóa. Vì nguyên tắc vàng các bạn phải nhớ “garbage in garbage out”, dữ liệu có thể được lưu dạng text, csv, sql server…. ứng với mỗi loại file ML.NET sẽ cung cấp các thư viện phù hợp để ta có thể tải dữ liệu đồng thời tự động mô hình hóa dữ liệu này thành mô hình hướng đối tượng. ở bước 1 thường sẽ làm công đoạn tải dữ liệu xong thì ta làm luôn công đoạn chia dữ liệu ban đầu thành 2 phần: Train set để huấn luyện mô hình (dùng cho bước 3), Test set để đánh giá mô hình (dùng cho bước 4). các dữ liệu được lưu vào IDataView object
- Bước 2: Tùy vào mục đích bài toán máy học mà ta dùng các giải thuật khác nhau, có thể dùng Binary classification, Multiclass classification, Regression…. (giải thuật nào là do mục đích nên khnog thể liệt kê hết, khi nào gặp thì tìm hiểu từng trường hợc cụ thể cho nó đỡ rắc rối). Bước này đại khái là chỉ định một quy trình hoạt động để trích xuất các đặc trưng và áp dụng thuật toán học máy cho phù hợp. Đối tượng tạo ra ở bước này là IEstimator
- Bước 3: Tiến hành train mô hình bằng cách gọi phương thức Fit() của IEstimator. kết quả của phương thức Fit() sẽ trả về một mô hình có kiểu ITransformer. Dữ liệu train là lấy Train set ở bước 1.
- Bước 4: Sau khi train mô hình xong thì chưa có sài ngay (thường là vậy), vì thường các bài toán máy học nó sẽ có kết quả dự đoán sai khác với thực tế, vấn đề là sự sai khác này có được chấp nhận hay không? có được tiếp tục sử dụng và tiếp tục cải tiến mô hình nữa hay không. Do đó khi train mô hình xong thì ta cần đánh giá mô hình này chất lượng ra sao. Ta sẽ lấy Test set ở bước 1 để đánh giá. Hàm đánh này tên là Evaluate() nó nằm trong các lớp giải thuật mà ta sử dụng để train mô hình, train mô hình dùng giải thuật nào thì khi đánh giá cũng dùng giải thuật đó. Ví dụ khi train mà ta dùng MulticlassClassification để train, thì khi đánh giá cũng dùng MulticlassClassification để đánh giá. Kết quả của hàmg Evaluate() sẽ trả về một object XYZMetrics. Với XYZ là giải thuật mà ta dùng để đánh giá, ví dụ dùng MulticlassClassification để đánh giá thì nó trả về MulticlassClassificationMetrics, dùng Regression để đánh giá thì nó lại trả về kết quả là RegressionMetrics… Nên sau khi gọi hàm đánh giá xong thì dựa vào các đối tượngkết quả trả về này mà ta quyết định xem có dùng mô hình này được hay không (trong máy học không có mô hình sai chỉ có mô hình phù hợp hay không). Ví dụ như mô hình đó dự đoán giá bán căn nhà là 1 tỉ, nhưng thực tế là 5 tỉ mới đúng giá, thì ráng mà chịu ai biểu không xem chất lượng mô hình có hợp lý hay không, với lại bán 1 tỉ cũng được mà chỉ là ít tiền thôi (nhưng là kỹ sư phần mềm cùng với am hiểu về cuộc sống thì chúng ta cũng điên điên có giới hạn thôi, nhường người khác điên với). Nếu bước 4 đánh giá mô hình mà không thấy nó ổn thì quay lại bước 1.
- Bước 5: Lưu mô hình, sau khi đã đánh giá mô hình chất lượng ở bước 4 rồi thì lưu lại để lần sau chỉ tải mô hình ra sài thôi, không phải chuẩn bị lại dữ liệu và train lại (vì các bước này rất tốt chi phí). File mô hình được lưu mặc định có đuôi .zip . ta gọi phương thức Save() để lưu
- Bước 6: Load mô hình đã được lưu ở bước 5. Ví dụ hôm qua lưu xong tắt máy, hôm nay mở máy lên thì chỉ cần tải lại mô hình đã chạy thôi, hoặc nhiệm vụ của ta là build model và đánh giá mô model cho chất lượng, rồi gửi model tới team khác sử dụng, thì muốn gửi đi được phải lưu được mô hình xuống ổ cứng đã chứ. Ta gọi hàm Load() để tải mô hình. Sau khi tải nó sẽ mô hình hóa ngược lại đối tượng ITransformer
- Bước 7: là gọi hàm CreatePredictionEngine().Predict() để sử dụng mô hình nhằm tìm ra kết quả dự báo của chương trình. Truyền đối tượng ITransformer ở bước 6 vào sài thôi.
Vậy bạn nắm quy trình 7 bước trước nha. sau khi lưu rồi thì lúc sử dụng ta chỉ cần làm 2 bước đó là bước 6 và bước 7. Rất tiện lợi.
Ví dụ code (hiển nhiên bạn xem để nắm cơ chế các bước Tui trình bày ở trên thôi, chứ giờ chưa cần hiểu code, Tui sẽ trình bày cách code chi tiết ở bài sau):
using System;
using System.Text;
using Microsoft.ML;
using Microsoft.ML.Data;
using static Microsoft.ML.DataOperationsCatalog;
class Program
{
public class HouseData
{
public float Size { get; set; }
public float Price { get; set; }
}
public class Prediction
{
[ColumnName("Score")]
public float Price { get; set; }
}
static void Main(string[] args)
{
Console.OutputEncoding= Encoding.UTF8;
MLContext mlContext = new MLContext();
//Bước 1. Chuẩn bị dữ liệu và chạy tạo train - test set data
HouseData[] houseData = {
new HouseData() { Size = 1.1F, Price = 1.2F },
new HouseData() { Size = 1.9F, Price = 2.3F },
new HouseData() { Size = 2.8F, Price = 3.0F },
new HouseData() { Size = 3.4F, Price = 3.7F },
new HouseData() { Size = 4.4F, Price = 7.7F },
new HouseData() { Size = 3.2F, Price = 3.2F },
new HouseData() { Size = 3.4F, Price = 3.8F },
new HouseData() { Size = 5.6F, Price = 8.1F },
new HouseData() { Size = 1.2F, Price = 1.4F },
new HouseData() { Size = 4.0F, Price = 6.5F },
new HouseData() { Size = 3.8F, Price = 5.9F }};
//load dữ liệu vài IDataView
IDataView alldata = mlContext.Data.LoadFromEnumerable(houseData);
//tách dữ liệu thành 2 phần 20% cho test, 80% cho train
TrainTestData splitDataView = mlContext.Data.TrainTestSplit(alldata, testFraction: 0.2);
// 2. Chọn giải thuật, rút trích đặc trưng cho tập dữ liệu
var pipeline = mlContext.Transforms.Concatenate("Features", new[] { "Size" })
.Append(mlContext.Regression.Trainers.Sdca(labelColumnName: "Price", maximumNumberOfIterations: 100));
// 3. Tiến hành train mô hình, gọi phần Train Set
var model = pipeline.Fit(splitDataView.TrainSet);
//4. train mô hình xong thì phải đánh giá nó
RegressionMetrics metrics = mlContext.Regression.Evaluate(splitDataView.TestSet,
labelColumnName: "Size", scoreColumnName: "Price");
//thông số này càng nhỏ càng tốt
Console.WriteLine("Root Mean Squared Error : " + metrics.RootMeanSquaredError);
//thông số này càng tịnh tiến tới 100% càng tốt
//trong kinh tế lượng họ cho rằng >=50% là ổn, nhưng không có nghĩa <50% là dở, nó có thể là số âm vô cùng
//ví dụ như chứng khoán nó sẽ nhảy búa xua
Console.WriteLine("RSquared: " + metrics.RSquared);
//5.giả sử mô hình ngon rồi thì lưu mô hình lại
mlContext.Model.Save(model, splitDataView.TrainSet.Schema, "housemodel.zip");
//6. Load mô hình lên để sài
//dĩ nhiên là bước 6,7 này nó nằm riêng chỗ khác, 1->5 lưu xong thì dẹp nó đi
//khi dùng chỉ quan tâm bước 6, và 7 thôi. Nhưng vì Tui hướng dẫn để 1 lèo 1->7 cho bạn hiểu
DataViewSchema modelSchema;
// Load trained model
var modelDaLuu = mlContext.Model.Load("housemodel.zip", out modelSchema);
//7. Gọi predict để dùng mô hình xem dự báo
var input = new HouseData() { Size = 2.5F };
var output = mlContext.Model.CreatePredictionEngine<HouseData, Prediction>(modelDaLuu).Predict(input);
Console.WriteLine("Nhà diện tích "+ input.Size +" được dự đoán có giá ="+ output.Price);
}
}
Root Mean Squared Eror : 0.2828426113221826
RSquared: -6.999914170176103
Nhà diện tích 2.5 được dự đoán có giá =3.3892932Kiến trúc lớp của ML.NET gồm những gì?
Để sử dụng ML.NET ta sẽ bắt đầu với đối tượng MLContext. Đối tượng này chứa các hàm/đối tượng để tải, lưu dữ liệu, chuyển đổi dữ liệu , trình huấn luyện và các thành phần vận hành mô hình. Mỗi đối tượng sẽ có các phương thức để tạo các loại thành phần khác nhau như:
| Chức năng | Lớp sử dụng |
| Data loading and saving | DataOperationsCatalog |
| Data preparation | TransformsCatalog |
| Binary classification | BinaryClassificationCatalog |
| Multiclass classification | MulticlassClassificationCatalog |
| Anomaly detection | AnomalyDetectionCatalog |
| Clustering | ClusteringCatalog |
| Forecasting | ForecastingCatalog |
| Ranking | RankingCatalog |
| Regression | RegressionCatalog |
| Recommendation | RecommendationCatalog |
| TimeSeries | TimeSeriesCatalog |
| Model usage | ModelOperationsCatalog |
Như vậy Ta lưu ý ứng với loại chức năng khác nhau thì ta dùng các lớp cho phù hợp, dĩ nhiên cũng không quan trọng lắm chỗ này, đừng ráng nhớ nhiều làm gì mệt óc, khi nào gặp tường hợp nào thì ta cắm đầu vào trường hợp đó mà tìm hiểu thôi. Tui do đi dạy cùng với đi làm nên phải ráng biết càng nhiều càng tốt.
Có những cách nào để lập trình được với ML.NET?
Hiện ta có khoảng 3 cách để lập trình với ML.NET, chúng gồm (hình nguồn Microsoft):

Như vậy ta có thể dùng ML.NET API (code), ML.NET Model Builder (dùng Visual Studio UI, xem bài), và ML.NET CLI (Cho cross platform)
Trong các bài hướng dẫn tới tui sẽ dùng chủ yếu cách số 1 ML.NET API (code)
Chúc các bạn thành công.
Bài viết gốc được đăng tải tại duythanhcse.wordpress.com
Có thể bạn quan tâm:
Ứng tuyển ngay nhiều việc làm IT hấp dẫn có trên TopDev
- T Thoughtworks: Nơi công nghệ chạm đích đến
- Đ Đại dương xanh cho Doanh nghiệp tăng trưởng bền vững trên Zalo
- L Lakehouse Architecture: Nền tảng dữ liệu cho ứng dụng AI trong tương lai
- G Giải Quyết Bài Toán Kinh Doanh Bằng Big Data và AI
- B BenQ RD Series – Dòng Màn Hình Lập Trình 4k+ Đầu Tiên Trên Thế Giới
- F Framework nào tốt nhất cho dự án của bạn? – Checklist chi tiết
- K Kinh nghiệm xử lý responsive table hiệu quả
- S Stackoverflow là gì? Bí kíp tận dụng Stack Overflow hiệu quả
- 7 7 kinh nghiệm hữu ích khi làm việc với GIT trong dự án
- B Bài tập Python từ cơ bản đến nâng cao (có lời giải)