Chia sẻ cơ bản sử dụng machine learning để giải quyết bài toán.
– Bước 1: bạn cần định nghĩa được model, bao gồm đầu vào, đầu ra, và hàm dự đoán, ở đây ví dụ là linear function y = ax + b, với deep learning là non-linear.
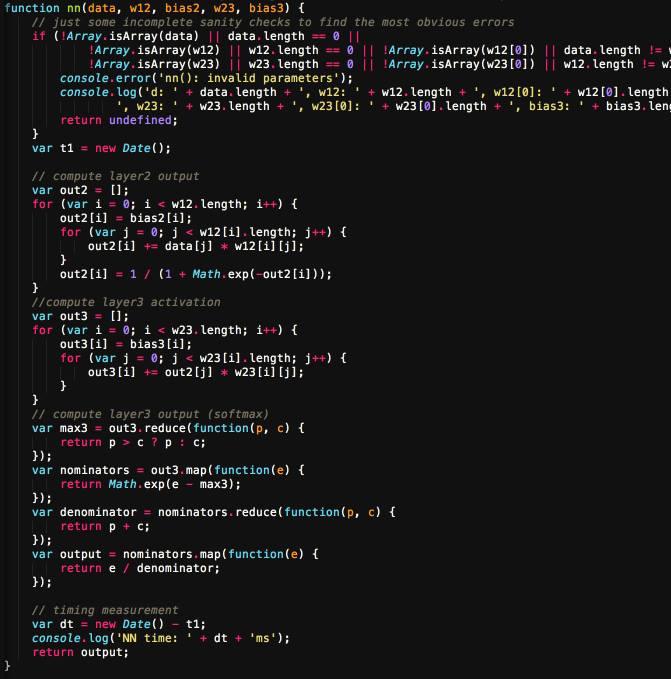
– Bước 2: bạn cần tính được sai lệch giữa đầu vào và đầu ra, ở đây gọi là loss, và cần optimize loss, ví dụ sử dụng đạo hàm [gradient descent optimizer], về cơ bản gọi là lim(y) = delta(y)/delta(x), sẽ tiến đến giới hạn.
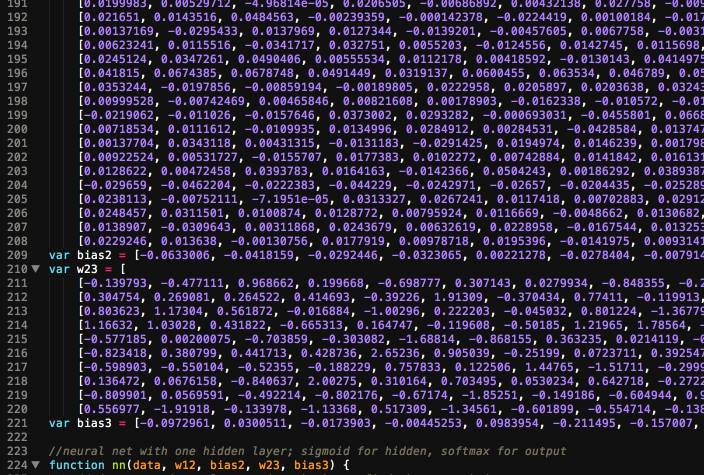
– Bước 3: bắt đầu quá trình train, về cơ bản là bạn có 1 không gian gồm số mẫu, và size của mẫu, là bộ số input_size + num_epchos, thực hiện việc tính giá trị loss và optimize nó tính lại được trọng số a,b của hàm prediction, quá trình này là estimator của learn phrase, khi đó giá trị loss này thường là rất nhỏ.
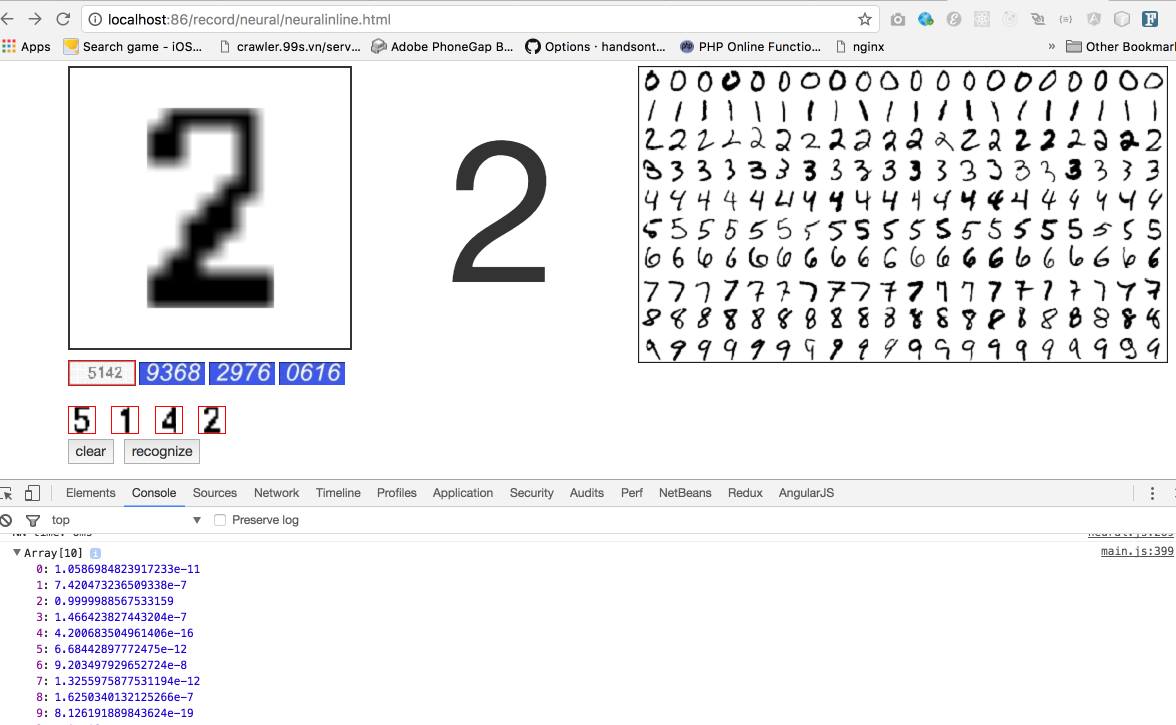
– Bước 4: thực hiện việc nhận dạng là đưa vào 1 input khác với số lặp ví dụ là 1, xét ví dụ là nhận dạng số, mảng loss của ta là mảng 10 phần tử, thì sẽ lấy giá trị loss nhỏ nhất tại vị trí của số tương ứng, đầu vào sẽ coi như là mảng 10 phần tử, số 1 tương ứng với [0,1,0,0,0,0,0,0,0,0,0]. Mạng có hidden layer đặt tên là bias.
Tham khảo thêm: Việc làm cho lập trình machine learning tại Topdev
Nguồn: Techtalk via thanhtupham
- T Thoughtworks: Nơi công nghệ chạm đích đến
- Đ Đại dương xanh cho Doanh nghiệp tăng trưởng bền vững trên Zalo
- L Lakehouse Architecture: Nền tảng dữ liệu cho ứng dụng AI trong tương lai
- G Giải Quyết Bài Toán Kinh Doanh Bằng Big Data và AI
- B BenQ RD Series – Dòng Màn Hình Lập Trình 4k+ Đầu Tiên Trên Thế Giới
- F Framework nào tốt nhất cho dự án của bạn? – Checklist chi tiết
- K Kinh nghiệm xử lý responsive table hiệu quả
- S Stackoverflow là gì? Bí kíp tận dụng Stack Overflow hiệu quả
- 7 7 kinh nghiệm hữu ích khi làm việc với GIT trong dự án
- B Bài tập Python từ cơ bản đến nâng cao (có lời giải)