Thiết kế hệ thống – Các hệ thống lớn như Facebook hoạt động như thế nào?
Bài viết được sự cho phép của tác giả Lê Nhật Thanh
Có bao giờ bạn thắc mắc, một website hoạt động như thế nào không? Trong bài này, chúng ta sẽ cùng tìm hiểu về kiến trúc website. Từ những web nhỏ cho tới những web lớn và khổng lồ.
Hay nói một cách khác. Những kĩ sư, lập trình viên đã làm như thế nào để làm ra được một website.
Một website đơn giản (như web của mình) hay đến một kiến trúc website phức tạp (như google, facebook, amazone,…) sẽ có kiến trúc như thế nào? Đây cũng là một câu hỏi phỏng vấn cho các lập trình viên, kĩ sư.
#1 Cấu trúc của một website
Để biết và hiểu được kiến trúc phức tạp của các website lớn. Chúng ta nên bắt đầu từ cái nhỏ nhất! Tìm hiểu một website đơn giản. À, website của mình cũng thuộc dạng là một website đơn giản. Vì nó là đơn thuần là một blog site. Chỉ xử lý về text và hình ảnh chứ không xử lý nhiều về nghiệp vụ.
Kiến trúc
Một website đơn giản hay phức tạp đều sẽ có hai thành phần chính: Client và Server. Nhưng những website đơn giản thì đương nhiên phần client và server của nó cũng đơn giản.
Mình sẽ cố gắng dùng những ngôn từ BÌNH DÂN nhất để giải thích cặn kẽ cho các bạn.
Client là những thứ bạn nhìn thấy trên browser (trình duyệt web).
Còn server là những gì xử lý ở phía sau mà người dùng bình thường không thấy được. Server sẽ được đặt ở một nơi nào đó và gửi dữ liệu về phía client cho người dùng thấy.
Và một lưu ý nữa, server là một phần cứng nhé. Nó y chang cái máy tính của bạn vậy (thật ra nó khác chút). Nó có CPU, RAM, ổ cứng và những “phụ kiện” khác!
Sau đây mình sẽ trình bày cụ thể hơn một chút về cách thức client và server hoạt động. Đương nhiên cũng ở mức cơ bản.
Khi bạn gõ Facebook.com thì chuyện gì xảy ra?
Bạn mở trình duyệt (Chrome chẳng hạn), gõ Facebook.com. Và bạn đơn thuần là… lướt Facebook. Chứ… ít khi bạn nghĩ về chuyện gì đã xảy ra để trang Facebook hiển thị ra cho bạn xem.
Nhưng ở trong bài viết này. Bạn sẽ phải tìm hiểu về điều đó.
Facebook.com được gọi là domain hay tên miền. Và phía sau domain này là một hệ thống server (khổng lồ). Khi bạn truy cập tới facebook.com. Nghĩa là bạn yêu cầu server của Facebook gửi cho bạn trang login để bạn đăng nhập. Và yêu cầu này được trình duyệt gửi tới Facebook server thông qua các gói tin.
Chúng ta gọi đây là một
HTTP requestgiữa trình duyệt và Facebook server. Sau đó, server nhận được yêu cầu của bạn. Nó tiến hành đọc và phân tích gói tin HTTP này. Và server sẽ trả lại cho trình duyệt trang login cũng thông qua HTTP response. Nói tóm lại là phía client và phía server giao tiếp với nhau thông qua giao thức HTTP.
Thôi, nhìn hình dưới cái là hiểu liền!

Trên đây là cách hoạt động tổng quan của một website. Ở mức độ mà ai ai cũng có thể hiểu. Ở trong phần sau, chúng ta sẽ đi sâu hơn về kiến trúc của một kiến trúc website lớn. Bởi vì một website lớn, phục vụ cho hàng triệu người dùng thì kiến trúc sẽ rất phức tạp.
#2 Mổ xẻ những thứ trong hệ thống website lớn
Như bạn cũng đã được học trong phần trên. Một hệ thống website sẽ có hai thành phần chính là client và server. Bạn cũng biết là ở dưới server sẽ lưu dữ liệu của website (để render ra cho phía client đó). Cho nên phần server chúng ta có thể tách ra làm 2 phần chính: webserver và database server.
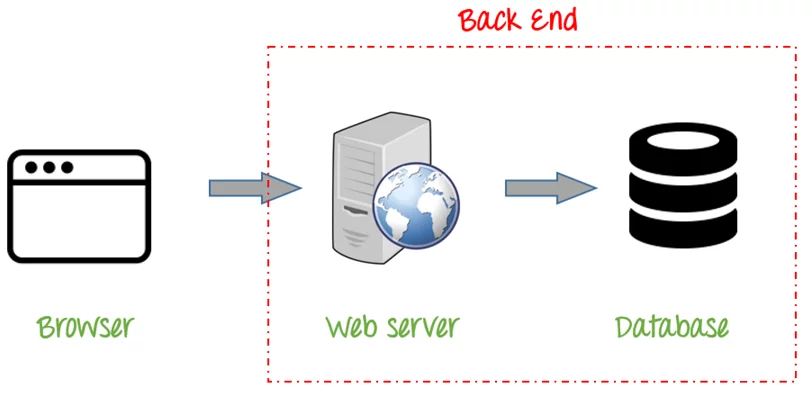
Web server sẽ chịu trách nhiệm tiếp nhận những yêu cầu từ browser. Và nó sẽ lấy những dữ liệu cần thiết dưới database server để trả về cho browser. Vì nơi lưu trữ dữ liệu của website sẽ là database server. Kiểu như bạn (browser) cần gì thì mình (web server) sẽ xuống database lấy cho bạn. Hiểu đơn giản vậy đó.
Tham khảo Web Developer Jobs HOT tại TopDev
Vấn đề khi lượng user tăng lên đột biến?
Và trước tiên mình muốn nói đến các website nhỏ, phục vụ ít người dùng trước.
Một website đơn giản, phục vụ ít người dùng, chỉ xử lý những tác vụ đơn giản. Thì họ không cần phải có một server KHỦNG. Vì điều đó là không cần thiết, vì sẽ tốn chi phí xây dựng server mạnh (vì nó là phần cứng mà).
Phần server của một website như thế thường có cấu hình bình thường (phục vụ đủ nhu cầu). Nhiều khi cả database server và web server cùng một nơi. Họ không tách hai phần này ra.
Cho nên những website có server như thế chỉ phục vụ cho một lượng người dùng nhất định.
Mình lấy ví dụ trong chính website của mình luôn. Giả sử cấu hình của một kiến trúc website chỉ đủ phục vụ cho khoảng 10.000 người dùng trong một lúc. Vậy nếu trong một lúc, website của mình có khoảng 1 triệu hay 10 triệu người dùng thì sao?
Câu trả là là TẠCH! Vì server không chịu nổi một lượng request lớn như vậy.
Vậy thì mình sẽ làm cách gì để có thể đáp ứng được lượng truy cập lớn như vậy?
TĂNG CẤU HÌNH SERVER LÊN chứ còn gì! Ví dụ gắn thêm RAM, gắn thêm core CPU, thay ổ cứng mạnh hơn chẳng hạn. Những giải pháp này sẽ giúp cho hệ thống website của bạn tăng đáng kể khả năng chịu tải.
Nhưng có một điều quan trọng. Phần cứng luôn có giới hạn của nó, chắc chắn là như thế. Cho nên bạn chỉ có thể tăng tốc độ xử lý ở server lên tới một giới hạn nào đó thôi. Không thể tăng mãi được!
Vậy thì mới có một câu hỏi được đặt ra. Những hệ thống như Facebook, Goolge, Youtube, Tiki,… đã làm cách nào để xử lý hàng triệu, hay hàng tỉ user. Vì đơn thuần với những hệ thống vậy. Một server có cấu hình cực mạnh cũng không thể chịu nổi lượng request khổng lồ như thế được. Vậy họ đã làm như thế nào với hệ thống của họ?
Một hệ thống lớn trên thực tế?
Đây cũng là một dạng câu hỏi / yêu cầu tuyển dụng đối với một senior developer. Câu hỏi kiểu như: “Xử lý hàng triệu người dùng một lúc không phải là vấn đề của bạn”.
Có thể bài này sẽ dài vì mình muốn trình bày rõ ràng nhất có thể về kiến trúc thực tế của một hệ thống.
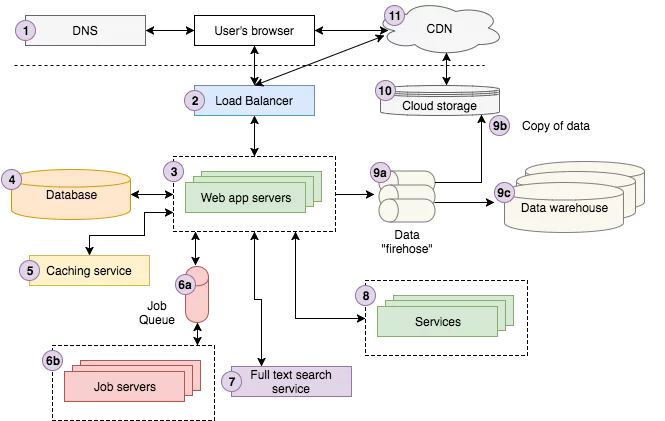
À, nhìn vào hình trên bạn hiểu không? Những senior developer có thể sẽ hiểu được toàn bộ bức hình trên. Nhưng mình muốn trình bày cho mọi developer đều hiểu về nó.
Ở phần đầu bài viết. Khi bạn gõ vào trình duyệt facebook.com, trình duyệt sẽ gửi yêu cầu của bạn tới server của Facebook. Bạn nhớ đoạn này chứ?
Vậy làm sao trình duyệt (browser) biết đường để tìm đến server của Facebook chỉ với tên miền facebook.com bạn đã cung cấp?
DNS server sẽ giúp trình duyệt… biết Facebook server nằm ở đâu.
DNS Server
Một server sẽ có một địa chỉ IP để định danh nó trên internet. Giống như địa chỉ nhà của bạn vậy.
Và Domain Name System (DNS) là một hệ thống phân giải tên miền. Giúp trình duyệt tìm ra được địa chỉ IP của một server thông qua tên miền.
Ở ví dụ trên, DNS sẽ giúp trình duyệt phân tích tên miền facebook.com. Và sau khi phân tích xong, DNS sẽ trả về cho trình duyệt IP của Facebook Server.
Tới đây thì trình duyệt đã biết sẽ gửi gói tin HTTP đến đâu rồi.
Tìm hiểu thêm DNS server ở đây.
Load Balancer
Chúng ta nhắc lại một chút về vấn đề lượng user request tăng lên đột ngột. Giải pháp ở đây là chúng ta sẽ phải mở rộng server (kiểu như nâng cấp).
Và cách nâng cấp ở trên, mình có đề cập đến chính là mở rộng thêm phần cứng cho một server. Và thuật ngữ của cách mở rộng này là vertical scaling (hay mở rộng theo chiều dọc). Cái này rõ ràng là có hạn chế vì phần cứng chỉ đạt đến một giới hạn nào đó thôi.
Và có một cách thứ hai để mở rộng server chính là horizontal scaling (hay mở rộng theo chiều ngang). Nghĩa là chúng ta mở rộng thêm nhiều server nữa song song với server hiện tại. Bây giờ server chúng ta không chỉ có một, mà có nhiều server chạy một lúc.
Rõ ràng là khi ta mở rộng server như vậy. Chúng ta có thể đẩy sức mạnh của server lên mức chúng ta mong muốn một cách dễ dàng (trên thực tế không dễ không ngen =]]] ). Vì đơn giản chúng ta chỉ việc lắp thêm những server khác song song thôi. “Một cây làm chẳng lên non, ba cây chụm lại nên hòn núi cao” mà.
Và việc mở rộng này nhằm mục đích chia sẻ tải giữa các server. Thậm chí khi có một server bị sự cố thì các server khác vẫn còn hoạt động.
Và lúc này vấn đề số lượng user tăng đã được giải quyết. Khi có cả triệu triệu request tới server, thì lượng request sẻ chia đều cho các server. Giúp server có thể đáp ứng được nhu cầu của người dùng. Nhìn hình bên dưới để hiểu nhé!
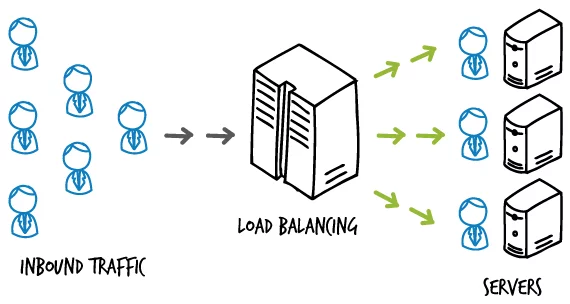
Và để phía server có thể làm được công việc chia sẻ tải này. Chúng ta có một công nghệ gọi là load balancer (cân bằng tải).
Khi client gửi request tới server, load balancer sẽ nhận request, rồi bắt đầu gửi request tới server nào thích hợp nhất.
Nói về lý thuyết thì rất là đơn giản. Những khi triển khai thực tế một hế thống server với load balancer là một điều CỰC KÌ KHÓ và phức tạp.
À ngoài ra chúng ta có thể lắp load balancer dự phòng nữa. Công nghệ này cực kì hay.
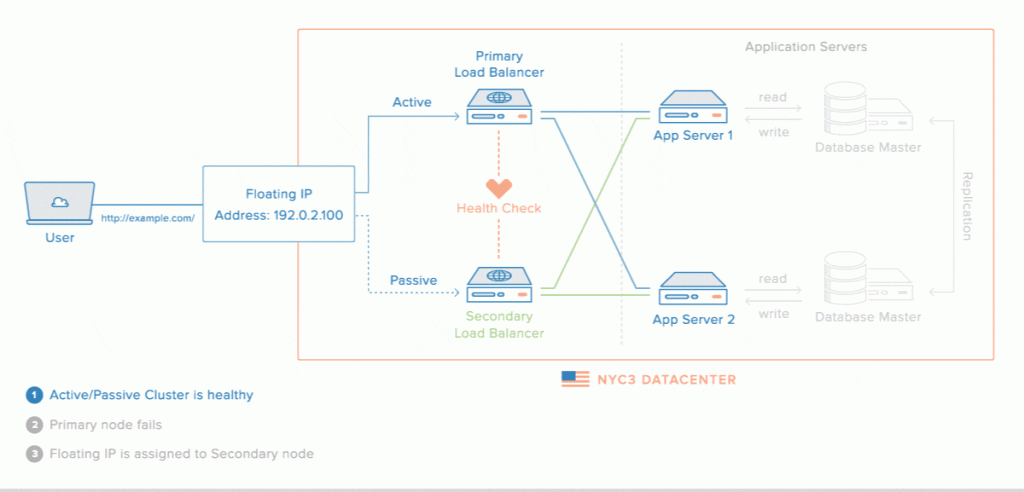
Web Server
Đây là phần server mà mình nói nảy giờ đó. Phần này là nơi xử lý logic (hay business logic). Các bạn backend-developer sẽ làm việc ở đây. Ở web server này, chúng ta hay dùng các ngôn ngữ như PHP, Nodejs, Java, .NET,… để xây dựng. Mình không nói nhiều về phần này nữa.
Database Servers
Phần này mình cũng đã từng nói rất cơ bản. Ở đây mình muốn mổ xẻ xâu hơn một xíu. Với một hệ thống lớn, phần database rất phức tạp.
Giả sử Facebook chỉ có một máy chủ để làm database server với hệ thống load balancer như trên. Rõ ràng hệ thống này cũng sẽ tạch. Như hình bên dưới!
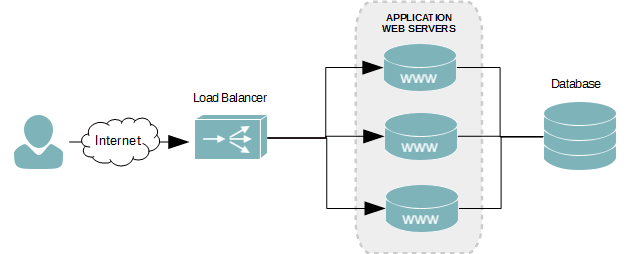
Rõ ràng khi bạn nhìn vào bức hình trên, nó quá đẹp. Nhưng ở đây, database sẽ chịu không nổi số lượng request của các web server. Rõ ràng đó cũng là một vấn đề tương tự với web server.
Chúng ta bắt buộc phải mở rộng database server! Nhưng mở rộng nó như thế nào? Không lẽ cứ tăng phần cứng cho nó lên cực hạn. Đây cũng không phải là cách giải quyết hay.
Ở đây chúng ta có một cách để mở rộng database. Dùng kiến trúc master/slave.
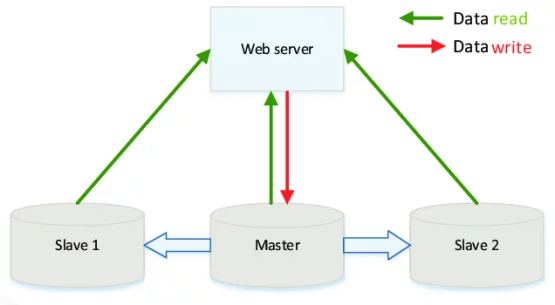
Master là database chính với mục đích là để ghi. Database master này sẽ có vài con slave (đệ tử) để nó đồng bộ dữ liệu qua. Và khi với lượng request lớn, chúng ta có thể đọc ở từng con server như vậy. Để đáng kể tải ở master. Đây là một cách cực kì hay.
Nhưng nó chỉ thích hợp với các hệ thống đọc database nhiều, ghi thì ít hơn. Bởi vì khi chúng ta ghi nhiều vào database thì master server cũng sẽ tạch vì chịu không nổi. Ví dụ như Facebook, lượng request ghi vào database cực kì nhiều (like, comment, chat, …). Cho nên chúng ta sẽ sinh ra thêm một cách mở rộng database khác – Sharding Database.
Ví dụ Facebook đi! Facebook sẽ có nhiều database nằm ở các nước khác khác nhau. Ở Việt Nam cũng có. Và giả sử các user Việt Nam muốn truy cập và database, thì phía server sẽ điều hướng làm sao đó để lương request này tới database nằm ở Việt Nam. Chúng ta hiểu đơn giản vậy thôi. Hiện nay có rất nhiều công nghệ hổ trợ chúng ta xây dựng Sharding Database như vậy! Bạn tìm hiểu thêm trên Google nhé!
Trên thực tế thì việc mở rộng database rất là khó, đòi hỏi các kĩ sư rất giỏi. Còn lý thuyết thì đơn giản như vậy thôi =]]].
Caching
Caching là một phần gì đó không thể thiếu đối với hầu hết các website hiện tại. Nếu bạn muốn tăng tốc website thì bạn không thể không nghĩ tới caching.
Nghĩ đơn giản như vậy. Mỗi khi trình duyệt request đến server, là mỗi lần server lại xuống database để lấy dữ liệu. Như vậy sẽ làm chậm trãi nghiệm duyệt web của bạn (vì query database thường sẽ chậm). Lúc đó chúng ta cần đến kĩ thuật caching. Hay hiểu đơn giản là nó lưu tạm dữ liệu ở một nơi nào đó (thường là RAM hay ổ cứng).
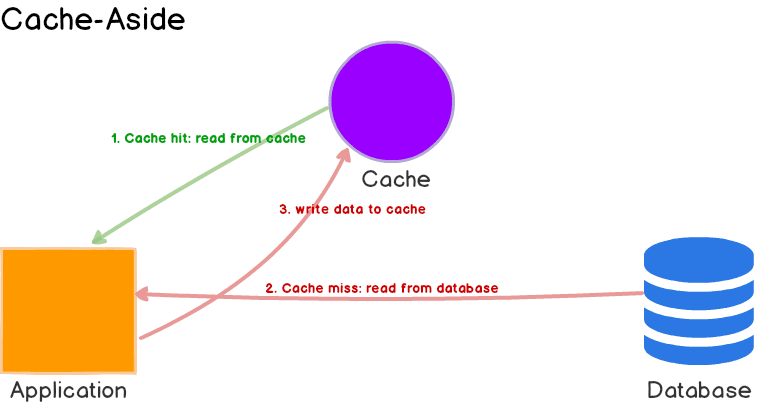
Khi chúng ta request tới server, server không cần phải mất công xuống database nữa mà vào thẳng cache server để lấy dữ liệu ra. Dữ liệu ở cache sẽ được đọc nhanh gấp nhiều lần. Nên tăng tốc một cách khủng khiếp.
Hiện tại có 2 hệ thống lưu trữ phổ biến là Redis và Memcache. Website của mình dùng Memcache ha!
Job Queues và Servers
Hầu hết ứng dụng web đều cần làm một số công việc bất đồng bộ ở phía back-end mà không kết hợp trực tiếp vào dữ liệu trả về cho người dùng. Ví dụ, Google cần crawl và index toàn bộ internet để trả về kết quả tìm kiếm cho chúng ta. Nó không được làm mỗi lần bạn tìm kiếm. Thay vào đó, nó crawl các trang web một cách bất đồng bộ, và cập nhật index theo thời gian (schedule).
Mặc dù có nhiều kiến trúc khác nhau cho các công việc bất đồng bộ, nhưng phố biến nhất là kiến trúc job queue. Nó chứa 2 thành phần: một hàng đợi job cần được chạy, và một hoặc nhiều job server (hay còn lại là worker) để chạy job trong hàng đợi.
Job queue chứa một danh sách job cần được chạy bất đồng bộ. Hàng đợi đơn giản nhất là FIFO (first in first out) mặc dù hầu hết ứng dụng sẽ cần một vài hàng đợi có ưu tiên (theo priority). Mỗi khi ứng dụng cần chạy job thì nó chỉ cần thêm job đó vào hàng đợi.
Một vài xử lý tường sử dụng kĩ thuật này: encode video và ảnh, xử lý file CSV, thống kê người dùng, gửi mật khẩu reset email,…
Job server xử lý job. Chúng thăm dò job queue để xác định có job cần làm hay không, và nếu có thì chúng sẽ đẩy job vào hàng đợi và thực thi nó.
Full-text Search Service
Hiểu đơn giản của dịch vụ này. Hệ thống website sẽ cho bạn một khung search. Và khi bạn search một vấn đề nào đó ví dụ “programming”, thì server sẽ trả cho bạn những kết quả trong database có liên quan tới programming ha.
Nhưng cứ mỗi lần server chúng ta đều phải query xuống database thì hơi “cực”. Nên các công nghệ full-text search ra đời để giúp trải nghiệm search nhanh hơn rất nhiều.
Nền tảng full-text search phổ biến nhất hiện nay là Eltasticsearch, bên cạnh một số lựa chọn khác như Sphinx hoặc Apache Solr.
Services
Khi hệ thống của chúng ta lớn dần lớn dần. Có một số services sẽ được chia nhỏ ra để chạy như một ứng dụng riêng, Web app và các Service khác có thể tương tác đến chúng. Ví dụ: Content service dùng để lưu trữ lượng dữ liệu lớn về video, ảnh, file audio. Payment service cung cấp giao diện để trả phí qua thẻ tín dụng, …
Data
Ngày nay, các công ty tồn tại hay phá sản dựa trên việc họ khai thác dữ liệu như thế nào. Khi các app đạt đến trạng thái hoạt động ổn định, nó sử dụng quy trình xử lý dữ liệu để chắc chắn rằng dữ liệu được thu thập, lưu trữ, phân tích. Một quy trình xử lý dữ liệu điện hình có ba giai đoạn:
- App gửi dữ liệu, thông qua tương tác user, đến
data firehoseđể lưu trữ và xử lý dữ liệu. Thường thì dữ liệu gốc được biến đổi hoặc tăng thêm và chuyển đến chofirehosekhác. AWS Kinesis và Kafka là hai công nghệ thường sử dụng cho mục đích này. - Dữ liệu gốc sau khi được biến đổi sẽ được lưu trữ trong
cloud storage. AWS Kinesis cung cấp thiết lập được gọi là firehose để lưu trữ dữ liệu gốc vào cloud storage (S3). - Dữ liệu đã biến đổi được đưa vào trong kho dữ liệu để phân tích. Sử dụng AWS Redshift sẽ giải quyết được việc này.
Cloud Storage
Cloud storage là cách đơn giản để lưu trữ, truy cập và chia sẻ dữ liệu trên Internet thông qua các nền tảng cloud như: AWS. Bạn có thể dùng nó để lưu trữ và truy cập đến mọi thứ bạn đã lưu trữ trên hệ thống thông tin cục bộ. Và có thể tương tác đến chúng qua Restful API.
Amazon S3 hiện nay là cloud storage phổ biến nhất để lưu trữ video, ảnh, audio, file css, js, …
CND
CDN viết tắt bởi Content Delivery Network là mạng lưới gồm nhiều máy chủ lưu trữ đặt tại nhiều vị trí địa lý khác nhau, cùng làm việc chung để phân phối nội dung, truyền tải hình ảnh, CSS, Javascript, Video clip, Real-time media streaming, File download đến user.
Cơ chế hoạt động của CDN giúp cho user truy cập nhanh vào dữ liệu máy chủ web gần họ nhất thay vì phải truy cập vào dữ liệu máy chủ web tại trung tâm dữ liệu.
Các hệ thống lớn như Facebook, Google đều sử dụng CDN để tăng trải nghiệm của user.
#Kết
Trên đây là mình đã trình bày dường như tổng quan về kiến trúc website của một hệ thống lớn. Và các vấn đề phát sinh trong quá trình xây dựng hệ thống để đáp ứng với lượng user không lồ. Rõ ràng lý thuyết là vậy, nhưng để thực hiện được những điều này phải có một đội ngũ cực giỏi.
Mình không hi vọng bạn hiểu hết các vấn đề trên. Đến cả bản thân mình cũng chưa hoàn toàn hiểu hết. Vì đơn giản mình chưa trải nghiệm qua tất cả các giai đoạn / công nghệ trên.
Nhưng mình muốn một phần nào giúp bạn có một cái nhìn tổng qua. Cũng như cung cấp các keyword cần thiết để bạn có thể tìm hiểu thêm trên internet.
Có thể bạn quan tâm:
- Messege Queue – Bộ phận không thể thiếu trong các hệ thống lớn và Microservice Architecture
- Top 6 nguyên lý thiết kế microservices cho lập trình viên có kinh nghiệm
- Cách Giao Tiếp Giữa Các Service Trong Hệ Thống Có Tải Cao
Xem thêm các việc làm CNTT hấp dẫn trên TopDev
- T Thoughtworks: Nơi công nghệ chạm đích đến
- Đ Đại dương xanh cho Doanh nghiệp tăng trưởng bền vững trên Zalo
- L Lakehouse Architecture: Nền tảng dữ liệu cho ứng dụng AI trong tương lai
- G Giải Quyết Bài Toán Kinh Doanh Bằng Big Data và AI
- B BenQ RD Series – Dòng Màn Hình Lập Trình 4k+ Đầu Tiên Trên Thế Giới
- F Framework nào tốt nhất cho dự án của bạn? – Checklist chi tiết
- K Kinh nghiệm xử lý responsive table hiệu quả
- S Stackoverflow là gì? Bí kíp tận dụng Stack Overflow hiệu quả
- 7 7 kinh nghiệm hữu ích khi làm việc với GIT trong dự án
- B Bài tập Python từ cơ bản đến nâng cao (có lời giải)