Bí kíp tạo ra một tokenizer về toán học bằng Javascript
Hồi trước, tôi đã rất hứng thú với việc viết ra một app chuyên giải các vấn đề liên quan tới toán học. Tôi cũng học được rằng mình phải phân tích cú pháp, yêu cầu thành một Cây cú pháp trừu tượng (abstract syntax tree). Vì vậy mà một bản thử đã được tạo ra bằng Javascript. Trong quá trình làm việc, tôi nhận ra rằng tokenizer cần phải được làm ra trước tiên. Vì thế mà hôm nay tôi sẽ chỉ bạn cách làm nó (Thấy có vẻ khó vậy thôi nhưng nó dễ lắm!)
Tokenizer là cái gì vậy?
Tokenizer là một chương trình chuyện phân chia một yêu cầu, hiển thị (expression) thành nhiều unit nhỏ gọi là Token. Nếu giờ tôi tự nói mình là “Thằng developer mập béo ụ” thì ta có thể sử dụng tokenizer theo nhiều cách sau:
Sử dụng từ ngữ giống như token:
0 => I’m 1 => a 2 => big 3 => fat 4 => developer
Sử dụng chữ cái làm token:
0 => I 1 => ‘ 2 => m 3 => a 4 => b … 16 => p 17 => e 18 => r
Hoặc là bao gồm luôn cả những kí hiệu khác như dấu phẩy, chấm và khoảng cách space:
0 => I 1 => ‘ 2 => m 3 => (space) 4 => a 5 => (space) 6 => b … 20 => p 21 => e 22 => r
Bạn hiểu rồi đúng không?
Tokenizers (còn gọi là lexer) được dùng cho việc phát triển của compiler cho ngôn ngữ lập trình. Nó giúp cho compiler tạo ra được những cấu trúc dựa theo những gì chúng ta muốn. Trong bài viết này thì đó là về cách biểu thị những thuật toán.
Tuyển dụng Javascript lương cao
Tokens
Một biểu thị thuật toán tốt bao gồm các token của thuật toán, mà trong project này thì sẽ là Literals, Variables, Operators hoặc Functions.
Một số điều cần lưu ý:
- Literal là một cái tên khá hoa mỹ cho một con số (trong ví dụ này). ta sẽ chỉ cho phép số ở dạng toàn bộ hoặc thập phân.
- Variable chính là các ẩn biến ta hay dùng trong toán: x,y,z,b,c. Cho project này, thì tất cả các variable sẽ chỉ hiện thị một chữ cái thôi. Đây cũng là cách để ta có thể token một biểu thị như ma là kết quả kết hợp từ hai variable m và a.
- Operator hoạt động trên Literal và Variable cũng như là kết quả của function. Chúng ta sẽ cho phép những operator +, -, *, /, và ^.
- Function giống như là phiên bản cao cấp của Operator. Nó bao gồm sin(), cos(), tan(), min(), max(), etc.
Ta cũng sẽ thêm vào 2 token vốn thường không được cho là token nhưng sẽ giúp ta dễ hơn trong việc quan sát: Left và Right Parentheses.
Một số điều cần lưu ý
Phép nhân ngầm (Implicit Multiplication)
Implicit multiplication đơn giản là cho phép người viết rút ngắn cách ghi ra phép tính nhân, 5x thay vì 5*x. Đi xa hơn nữa, nó cũng cho phép với những function như (5sin(x) = 5*sin(x)).
Không chỉ thế, 5(x) và 5(sin(x)) cũng đều làm được. Tất cả đều tùy vào chúng ta có cho phép nó hay không thôi. Vậy thì có bất lợi gì không? Việc không dùng nó thật ra lại giúp quá trình tokenize diễn ra nhanh hơn cũng như cho phép variable có tên với nhiều kí tự hơn (những cái tên như price) Còn nếu bạn cho phép thì sẽ giúp platform dễ nhìn hơn cho người dùng, cho thêm thách thức để bạn chứng minh bản lĩnh. Tôi thì sẽ cho phép nó.
Syntax
Mặc dù chúng ta không phải là đang tạo ra một ngôn ngữ lập trình mới, nhưng cũng phải có một vài rules qui định cho các biểu thị đúng, để người dùng biết phải điền vào như thế nào mà ta cũng biết cái gì cần để lên kế hoạch. Nói chính xác hơn, các token toán học phải được kết hợp dựa theo những qui tắc của thuật toán để đưa ra những biểu thị đúng. Sau đây là những qui tắc của tôi:
Token có thể được chia cắt bởi o hoặc dùng khoảng trống space nhiều lần.
2+3, 2 +3, 2 + 3, 2 + 3 are all OK 5 x - 22, 5x-22, 5x- 22 are all OK
Nói cách khác, khoảng cách không quan trọng.
Các hàm function sẽ phải được đặt trong ngoặc đơn (sin(y), cos(45), chứ không phải sin y, cos 45) (Tại sao? chúng ta sẽ lược bỏ tất cả các dấu space ra khỏi string vì thế mà bạn sẽ muốn thấy được khi nào hàm bắt đầu và kết thúc)
Phép nhân ngầm chỉ được dùng giữa Literals và Variables hoặc Literals và Functions, theo đúng thứ tự đó (Literal luôn được ưu tiên trước) và được quyền có hoặc không ngoặc đơn. Điều đó cũng có nghĩa:
- a(4) sẽ được xem là một hàm – function hơn là a*4
- a4 không được cho phép
- 4a và 4(a) thì lại được
Giờ thì thử thực hành cái nào!
Đầu tiên ta sẽ bắt đầu với cơ bản trước với ví dụ này: 2y + 1
Để biểu thị dãi trên trong một array với các token sẽ như thế này:
0 => Literal (2) 1 => Variable (y) 2 => Operator (+) 3 => Literal (1)
Trước tiên, ta sẽ xác định một token class để cho nó dễ:
function Token(type, value) {
this.type = type;
this.value = value
}
Algorithm – Thuật toán
Giờ thì tới phần khung xương cho chức năng của tokenizer.
Tokenizer của chúng ta sẽ đi qua từng kí tự của str array và tạo ra token dựa trên những gì nó thu thập được.
[Ta sẽ tự cho là người dùng đã đưa những bài toán và biểu thị đúng nên việc sử dụng hình thức xác nhận sẽ không cần đưa vào trong xuyên suốt project này]
function tokenize(str) {
var result=[]; //array of tokens
// remove spaces; remember they don't matter?
str.replace(/\s+/g, "");
// convert to array of characters
str=str.split("");
str.forEach(function (char, idx) {
if(isDigit(char)) {
result.push(new Token("Literal", char));
} else if (isLetter(char)) {
result.push(new Token("Variable", char));
} else if (isOperator(char)) {
result.push(new Token("Operator", char));
} else if (isLeftParenthesis(char)) {
result.push(new Token("Left Parenthesis", char));
} else if (isRightParenthesis(char)) {
result.push(new Token("Right Parenthesis", char));
}
});
return result;
}
Đoạn code trên rất là cơ bản. Những helper như isDigit() , isLetter(), isOperator(), isLeftParenthesis(), and isRightParenthesis() sẽ được
function isDigit(ch) {
return /\d/.test(ch);
}
function isLetter(ch) {
return /[a-z]/i.test(ch);
}
function isOperator(ch) {
return /\+|-|\*|\/|\^/.test(ch);
}
function isLeftParenthesis(ch) {
return /\(/.test(ch);
}
function isRightParenthesis(ch) {
return /\)/.test(ch);
}
[Bạn có thể thấy không hề có isFunction(), isLiteral() hoặc isVariable() functions bởi chúng ta sẽ kiểm tra các character từng đứa một]
Và giờ đây parser của chúng ta đã thật sự hoạt động. Hãy thử tất cả những phép tính sau: 2 + 3, 4a + 1, 5x+ (2y), 11 + sin(20.4).
Tất cả đều chạy tốt?
Không hẳng.
Bạn sẽ thấy với phép tính cuối, 11 sẽ được báo là 2 Literal tokens chứ không phải 1. Ngoài ra sin cũng được báo là có 3 token chứ không phải 1. Tại sao?
đó vì khi tokenize, một số token có nhiều kí tự. Literals có thể là 5, 7.9, .5 trong khi Functions thì là sin, cos etc. Variables thì mặc dù chỉ được hiện dùng 1 kí tự nhưng lại là chuyện hoàn toàn khác trong implicit multiplication. Vậy làm cách nào để sửa nó?
Buffers
Bằng cách dùng một buffer ta có thể giải quyết những vấn đề này. Và trong ví dụ thì trên ta sẽ cần đến 2. một buffer sẽ dùng cho các kí tự của Literal (số và dấu thập phân), và một cái khác cho chữ cái (bao gồm cho cả variables và functions).
Buffer hoạt động như thế nào? Khi tokenizer gặp một số/dấu thập phân hoặc chữ cái, nó sẽ đặt chúng vào buffer thích hợp và quá trình đó lặp đi lặp lại cho đến khi nó tiến vào một operator hoàn toàn khác. Đồng thời hành động của tokenizer cũng thay đổi tùy vào từng operator.
Đối với một phép toán sau 456.7xy + 6sin(7.04x), thì ta sẽ có được như dưới đây:
read 4 => numberBuffer read 5 => numberBuffer read 6 => numberBuffer read . => numberBuffer read 7 => numberBuffer x is a letter, so put all the contents of numberbuffer together as a Literal 456.7 => result read x => letterBuffer read y => letterBuffer + is an Operator, so remove all the contents of letterbuffer separately as Variables x => result, y => result + => result read 6 => numberBuffer s is a letter, so put all the contents of numberbuffer together as a Literal 6 => result read s => letterBuffer read i => letterBuffer read n => letterBuffer ( is a Left Parenthesis, so put all the contents of letterbuffer together as a function sin => result read 7 => numberBuffer read . => numberBuffer read 0 => numberBuffer read 4 => numberBuffer x is a letter, so put all the contents of numberbuffer together as a Literal 7.04 => result read x => letterBuffer ) is a Right Parenthesis, so remove all the contents of letterbuffer separately as Variables x => result
Hoàn tất. Giờ thì bạn đã hiểu được rồi đúng không?
Đây là lúc mà bạn sẽ phải suy nghĩ kĩ về thuật toán và mô hình hóa dữ liệu
của mình. Sẽ có chuyện gì xảy ra nếu kí tự hiện tại lại là một operator, và Buffer cho số lại không empty? Liệu cả 2 buffer đều có thể cùng lúc /lần lượt không empty không?
Từ đó chúng ta sẽ rút ra được kết quả sau (giá trị ở bên trái của mũi tên miêu tả kí tự/nhân vật hiện tại của chúng ta (ch), NB=numberbuffer, LB=letterbuffer, LP=left parenthesis, RP=right parenthesis)
loop through the array: what type is ch? digit => push ch to NB decimal point => push ch to NB letter => join NB contents as one Literal and push to result, then push ch to LB operator => join NB contents as one Literal and push to result OR push LB contents separately as Variables, then push ch to result LP => join LB contents as one Function and push to result OR (join NB contents as one Literal and push to result, push Operator * to result), then push ch to result RP => join NB contents as one Literal and push to result OR push LB contents separately as Variables, then push ch to result end loop join NB contents as one Literal and push to result OR push LB contents separately as Variables,
2 điều cần lưu ý
- Bạn có thấy tôi đã thêm vào “push Operator * to result” không? Đó là cách chúng ta chuyển đổi phép nhân ẩn thành phép nhân rõ ràng. Và khi làm trống nội dung của các LB riêng biệt như Variable, ta cần phải chèn multiplication Operator vào giữa chúng.
- Tại cuối function loop, ta cũng phải làm trống tất cả những gì còn sót lại trong buffer.
Giờ thì chuyển nó thành code thôi!
Tổng hợp lại tất cả, tokenize function của bạn sẽ nhìn như thế này:
function Token(type, value) {
this.type = type;
this.value = value;
}
function isDigit(ch) {
return /\d/.test(ch);
}
function isLetter(ch) {
return /[a-z]/i.test(ch);
}
function isOperator(ch) {
return /\+|-|\*|\/|\^/.test(ch);
}
function isLeftParenthesis(ch) {
return /\(/.test(ch);
}
function isRightParenthesis(ch) {
return /\)/.test(ch);
}
function tokenize(str) {
str.replace(/\s+/g, "");
str=str.split("");
var result=[];
var letterBuffer=[];
var numberBuffer=[];
str.forEach(function (char, idx) {
if(isDigit(char)) {
numberBuffer.push(char);
} else if(char==".") {
numberBuffer.push(char);
} else if (isLetter(char)) {
if(numberBuffer.length) {
emptyNumberBufferAsLiteral();
result.push(new Token("Operator", "*"));
}
letterBuffer.push(char);
} else if (isOperator(char)) {
if(numberBuffer.length) {
emptyNumberBufferAsLiteral();
}
if(letterBuffer.length) {
emptyLetterBufferAsVariables();
}
result.push(new Token("Operator", char));
} else if (isLeftParenthesis(char)) {
if(letterBuffer.length) {
result.push(new Token("Function", letterBuffer.join("")));
letterBuffer=[];
} else if(numberBuffer.length) {
emptyNumberBufferAsLiteral();
result.push(new Token("Operator", "*"));
}
result.push(new Token("Left Parenthesis", char));
} else if (isRightParenthesis(char)) {
if(letterBuffer.length) {
emptyLetterBufferAsVariables();
} else if (numberBuffer.length) {
emptyNumberBufferAsLiteral();
}
result.push(new Token("Right Parenthesis", char));
}
});
if (numberBuffer.length) {
emptyNumberBufferAsLiteral();
}
if(letterBuffer.length) {
emptyLetterBufferAsVariables();
}
return result;
function emptyLetterBufferAsVariables() {
var l = letterBuffer.length;
for (var i = 0; i < l; i++) {
result.push(new Token("Variable", letterBuffer[i]));
if(i< l-1) { //there are more Variables left
result.push(new Token("Operator", "*"));
}
}
letterBuffer = [];
}
function emptyNumberBufferAsLiteral() {
result.push(new Token("Literal", numberBuffer.join("")));
numberBuffer=[];
}
}
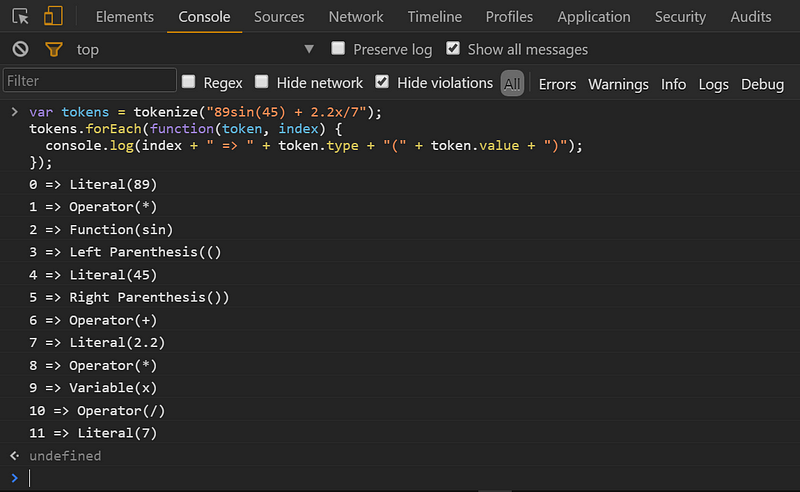
var tokens = tokenize("89sin(45) + 2.2x/7");
tokens.forEach(function(token, index) {
console.log(index + " => " + token.type + "(" + token.value + ")");
});
Thấy chưa? Nó hoạt động rồi đấy!
Tổng kết
Đến giờ phút này thì là lúc bạn sẽ phân tích function của mình và xem nó làm những gì so với những gì bạn muốn. Hãy luôn tự hỏi bản thân, “Liệu nó có hoạt động đúng như mục tiêu đặt ra không?” và “Liệu mình đã dự đoán hết trường hợp có thể xảy ra chưa?”
Tiếp theo bạn sẽ phải chạy nhiều bài test khác nhau cho function. Nếu bạn thấy hài lòng với kết quả thì mới bắt đầu suy nghĩ về hướng cải thiện nó thêm.
Nguồn: topdev.vn via Medium
Tuyển dụng IT đãi ngộ tốt trên TopDev
- T Thoughtworks: Nơi công nghệ chạm đích đến
- Đ Đại dương xanh cho Doanh nghiệp tăng trưởng bền vững trên Zalo
- L Lakehouse Architecture: Nền tảng dữ liệu cho ứng dụng AI trong tương lai
- G Giải Quyết Bài Toán Kinh Doanh Bằng Big Data và AI
- B BenQ RD Series – Dòng Màn Hình Lập Trình 4k+ Đầu Tiên Trên Thế Giới
- F Framework nào tốt nhất cho dự án của bạn? – Checklist chi tiết
- K Kinh nghiệm xử lý responsive table hiệu quả
- S Stackoverflow là gì? Bí kíp tận dụng Stack Overflow hiệu quả
- 7 7 kinh nghiệm hữu ích khi làm việc với GIT trong dự án
- B Bài tập Python từ cơ bản đến nâng cao (có lời giải)