AI và những điều bạn cần phải có trước khi đụng tới AI
Cũng như các công nghệ khác, AI đã thổi bùng lên sự sợ hãi lạc hậu, không bắt kịp với xu thế của các Developer. Và cả cộng đồng về IT đều luôn dõi theo các tin tức về AI hằng ngày. Từ hardware startups cho tới những người khổng lồ công nghệ hay các tổ chức cộng đồng, mọi người đều thi nhau làm và phát triển AI của họ. Và tất nhiên câu hỏi quan trọng vẫn luôn là: “ Cách áp dụng AI và machine learning vào cải thiện hiệu năng công việc của chúng ta”.
Đa phần các công ty vẫn chưa sẵn sàng với AI. Có thể là bởi công ty chỉ mới bắt đầu vào lĩnh vực này, hoặc việc đọc và phân tích dữ liệu đối với họ không quan trọng. Nhưng phần lớn là do cơ sở vật chất không đủ tầm để áp dụng AI và hưởng lợi từ nó.
Là một chuyên gia tư vấn về data science/AI, tôi đã phải nói những điều trên biết bao nhiêu lần, đặc biệt là trong 2 năm vừa qua. Thật sự việc phải nhận ra AI không cần thiết với công ty cũng như là chấp nhận sự thật rằng mình vẫn còn quá yếu. Vậy làm cách nào để thuyết phục họ?
Tôi thường sử dụng phương thức “kim tự tháp” với AI đứng trên đỉnh. Bạn chỉ có thể xây được cái đỉnh nếu có được phần thân và chân, hay nói cách khác là dữ liệu và cơ sở vật chất.
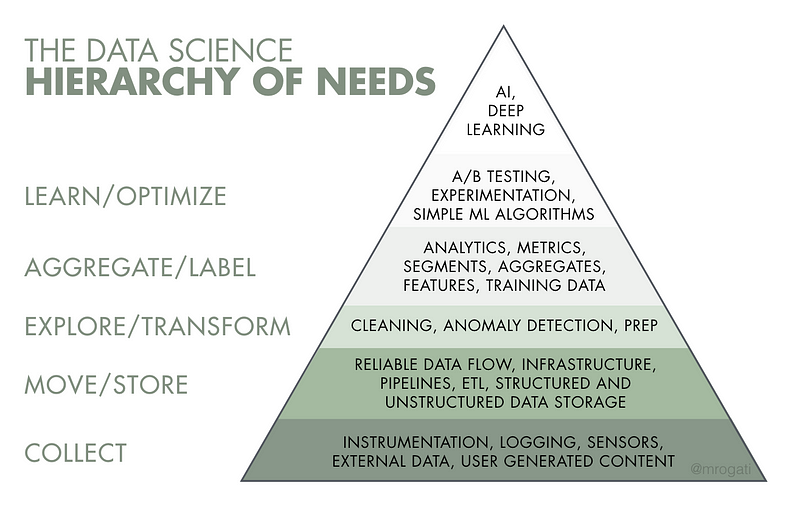
Nhu cầu tổi thiểu: bạn có thể đếm được không?
Ở chân kim tự tháp, chúng ta có data collection (thu thập dữ liệu). Bạn cần Data gì? và Data nào có sẵn? Nếu sản phẩm có liên quan tới khách hàng, bạn có thu thập được những tương tác từ user chưa? Bởi cuối cùng, với dataset đúng thì những tiến bộ trong machine learning mới có thể đạt được.
Tiếp theo, data di chuyển như thế nào qua khắp hệ thống? Bạn có dòng streams / ETL tốt không? Bạn lưu trữ dữ liệu ở đâu và nó có dễ truy cập và lấy thông tin không? Jay Kreps đã luôn nhấn mạnh rằng, dòng data ổn định và đáng tin cậy mới chính là chìa khóa cho việc sử dụng data một cách hiệu quả.
Chỉ khi data có thể được truy cập thì bạn mới có thể sử dụng và biến đổi nó được, bao gồm ‘data cleaning’, một lĩnh vực khá quan trọng của AI nhưng lại ít người quan tâm tới. Và khi làm về AI, bạn mới nhận ra mình đã bỏ lỡ biết bao nhiêu data, cảm biến của bạn không hề đáng tin cậy, mỗi phiên bản update là lại xuất hiện biết bao nhiêu vấn đề.
Cho đến khi nào bạn có thể khai thác và lọc data một cách hiệu quả nhất thì mới bắt đầu chuyển qua phân tích chúng (hay còn gọi là BI): xác định các metrics khác nhau để theo dõi, sự ảnh hưởng từ nhiều yếu tố khác nhau lên chúng. Vì mục đích của ta là tạo ra AI, những quá trình trên sẽ trở thành những tính năng quan trọng cho machine learning model của bạn. Cũng trong giai đoạn này, bạn có thể bắt đầu chuẩn bị cho training data với các labels khác nhau. Đây cũng là giai đoạn khá thú vị bởi những sự thật được phản ánh từ data.
OK! Anh cuối cùng cũng đếm được rùi! Giờ thì làm gì tiếp?
Và khi đã có training data , bây giờ ta đã có thể làm machine learning rùi đúng không? Tùy vào mục đích của bạn, nếu là để suy đoán churn thì được nhưng nếu có liên quan tới tương tác user thì không. Chúng ta cần có A/B testing và framewor thử nghiệp, thực hiện từng bước một nhằm bảo đảm không gặp phải sai phạm quá lớn và kết quả chính xác nhất có thể. Đây cũng là giai đoạn để bạn dặt ra các baseline đơn giản.
Bạn có thể deploy các thuật toán ML đơn giản (như logistic regression hoặc division), sau đó hãy nghĩ về những dấu hiệu và tính năng có thể ảnh hưởng tới kết quả của bạn. Weather & census data là lựa chọn hàng đầu của tôi. Bởi mặc dù rất là mạnh mẽ, deep learning lại không hề tự động làm những việc trên cho bạn. Việc đưa vào các tính năng mới sẽ giúp cải thiện hiệu năng rất lớn. Vì thế mà bạn cần phải dành nhiều thời gian cho mảng này trước khi vào giai đoạn tiếp theo.
Cuối cùng cũng đụng tới AI!
Bạn đã làm được rùi đấy. Bạn rất khiêm tốn và tài giỏi. data của bạn vừa gọn gàng và sạch sẽ. Dashboards, labels and những tính năng tốt đều có mặt. Bạn cẩn thận trong việc testing và baseline của bạn quá ư là chuẩn. Bạn đã thật sự sẵn sàng. Hãy thoải mái thử tất cả mọi thứ, từ mới nhất cho đến hiện đại nhất. Bạn có thể nhận được sự cái thiện rất lớn hoặc không. Trường hợp tệ nhất thì bạn vẫn học được phương pháp mới, thêm kinh nghiệm và hiểu biết. Còn nếu bạn may mắn thì user, client cũng như công ty của bạn sẽ nhận được rất nhiều lợi ích.
Ủa vậy còn MVPs, Agile, Lean và mấy cái khác thì sao?
Tạo ra AI là một quá trình đầy phức tạp mà bạn sẽ mất rất nhiều thời gian. Cũng giống như khi tạo ra một MVP (minimally viable product), bạn bắt đầu từ một nhánh nhỏ và bảo đảm sản phẩm hoạt động thật tốt trước. Sau đó thì hãy áp dụng model kim tự tháp cũng như mở rộng nó ra. Ví dụ như tại Jawbone, chúng tôi bắt đầu với sleep data và tạo ra kim tự tháp bao gồm instrumentation, ETL, cleaning & organization, label capturing và definitions, metrics. Sau đó chúng tôi tiếp tục phát triển và mở rộng ra. Bài học ở đây là chúng tôi luôn làm kĩ lưỡng và phải bảo đảm sản phẩm chính vẫn luôn được hoạt động tốt trước khi đụng tới AI.
Nguồn: Topdev via Hackernoon
- T Thoughtworks: Nơi công nghệ chạm đích đến
- Đ Đại dương xanh cho Doanh nghiệp tăng trưởng bền vững trên Zalo
- L Lakehouse Architecture: Nền tảng dữ liệu cho ứng dụng AI trong tương lai
- G Giải Quyết Bài Toán Kinh Doanh Bằng Big Data và AI
- B BenQ RD Series – Dòng Màn Hình Lập Trình 4k+ Đầu Tiên Trên Thế Giới
- F Framework nào tốt nhất cho dự án của bạn? – Checklist chi tiết
- K Kinh nghiệm xử lý responsive table hiệu quả
- S Stackoverflow là gì? Bí kíp tận dụng Stack Overflow hiệu quả
- 7 7 kinh nghiệm hữu ích khi làm việc với GIT trong dự án
- B Bài tập Python từ cơ bản đến nâng cao (có lời giải)