3 Hiểu Lầm Về XPath Trong Web Automation
Bài viết được sự cho phép của vntesters.com
Nhận diện web elements (element identification) là bước không thể thiếu khi automate web testing. XPath (được W3C khuyên dùng) chính là giải pháp tối ưu cho vấn đề này. Đa số các web automation tools đều hỗ trợ XPath, kể cả Selenium WebDriver. Dù vậy, sử dụng XPath hiệu quả thành thục không dễ, đòi hỏi nhiều thời gian tìm hiểu và “khổ luyện”.
Bài viết sẽ giúp bạn vén bức màn bí ẩn về 3 lỗi lầm thường gặp khi sử dụng XPath và cách khắc phục chúng. Hy vọng bạn có thể tận dụng được tối đa sức mạnh của “vũ khí bí mật” này.
[1] XPath là property của web element
Hiểu XPath bằng phép so sánh này là xu hướng tự nhiên khi bạn mới học về XPath. Nhưng dần dần bạn sẽ thấy cách hiểu tương tự đó khá nguy hiểm. Giả dụ bạn copy XPath của 1 button (<input>) trên Chrome bằng cách right click lên web element và chọn Copy > Copy XPath:
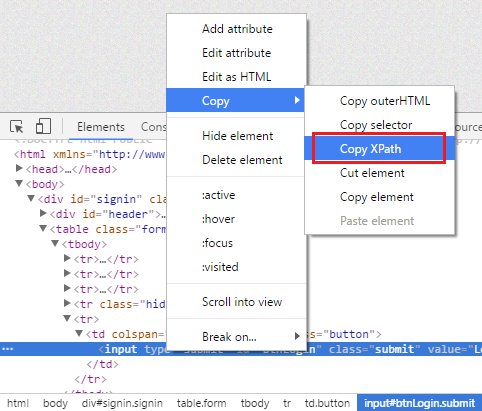
Bạn sẽ nhận được chuỗi sau:
//*[@id=”Login”]
Trong khi đó, nếu bạn dùng Firebug (1 add-on của Firefox) trên cùng button, bạn sẽ nhận được kết quả hoàn toàn khác biệt:
/html/body/div/table/tbody/tr[5]/td/input
Tại sao XPath “property” của cùng 1 web element lại không hề giống nhau chút nào, dù web element này không thay đổi?
Bởi vì XPath thực sự không phải là “property” của control. Theo định nghĩa, XPath chỉ là ngôn ngữ để miêu tả cách tìm kiếm 1 web element mà thôi. Do vậy, những tools khác nhau trả về XPath của 1 web element hoàn toàn khác nhau là chuyện “bình thường như bức tường”.
Điều này ngầm định rằng bạn phải là người quyết định XPath nào dễ đọc (readable) và ổn định (reliable) nhất để locate 1 web element.
Một số test automation tools như TestArchitect (sản phẩm của LogiGear) cung cấp sẵn chức năng construct XPath “đẹp”. Screenshot bên dưới minh họa XPath mà TestArchitect gợi ý cho bạn (cùng chỉ đến button trong 2 ví dụ phía trên).
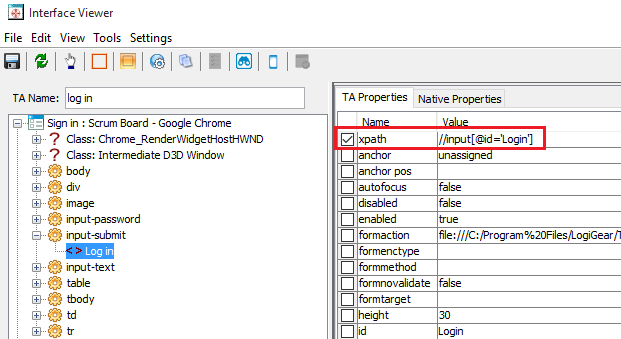
Đường dẫn này (//input[@id=’Login’]) “đẹp” hơn bởi vì:
- Chi tiết hơn gợi ý từ Chrome (//*[@id=”Login”]). Đường dẫn của Chrome sẽ chấp nhận tất cả elements có ID = “Login” dù element đó thuộc loại gì. Giả sử trang web có 1 element <td> cùng ID = “Login”, đường dẫn Chrome có thể trả về kết quả sai.
- Ít “dễ vỡ” hơn gợi ý từ Firebug (/html/body/div/table/tbody/tr[5]/td/input). Giả sử <input> tag này được developer đổi sang <tr> thứ 8, đường dẫn Firebug sẽ trả về rỗng (null).
Dù XPath nào có “đẹp” đến đâu đi nữa, bạn vẫn phải là người quyết định cuối cùng.
[2] XPath không ổn định
Ấn tượng này cũng dễ hiểu vì đôi lúc test run của bạn fail trên Firefox vì ban đầu bạn capture trên Chrome và ngược lại. Cẩn thận điều tra một chút bạn sẽ thấy có sự khác biệt.
Trên Chrome:
//input[@id=’stdinput-00001′]
Trên Firefox:
//input[@id=’stdinput-0000A’]
Đây có thể là kết quả của việc developer generate elements động, một kỹ thuật khá phổ biến khi phát triển web apps. Có thể trong lúc code, anh chàng developer nào đó đã gắn liền việc tạo web elements vào loại browser. Đây là việc làm đi ngược với tiêu chí tăng testability. Dù vậy, đôi lúc lỗi lầm vẫn xảy ra.
Nếu bạn không để ý kỹ, bạn có thể đổ lỗi cho XPath. Nhưng thực tế kẻ tội đồ không phải XPath mà là cách generate ID cho controls đặc dị trên. Trong lúc chờ đợi developer fix sự bất đồng bộ này để tăng testability, bạn có thể tiếp tục công việc testing bằng 1 thủ thuật nho nhỏ như sau:
//input[contains(@id, ‘stdinput-00001‘) or contains(@id, ‘stdinput-0000A‘)]
Chúc mừng! Tests của bạn đã có thể chạy thành công trên cả 2 browsers.
[3] XPath là “silver bullet”
Trong tiếng Anh, cụm từ “silver bullet” miêu tả 1 giải pháp one size fits all (một câu trả lời cho mọi vấn đề). Phụ thuộc vào XPath quá mức mà không cẩn thận phân tích và thấu hiểu web apps bạn đang test sẽ làm bạn hết sức ngỡ ngàng khi nhận được kết quả failed bất ngờ. Cần hiểu rằng cùng 1 XPath có thể trả về nhiều elements khác nhau tùy vào tình huống. Ví dụ:
//a[.=’Mac’]
Khi bạn dùng XPath trên, bạn muốn lấy <a> element này:
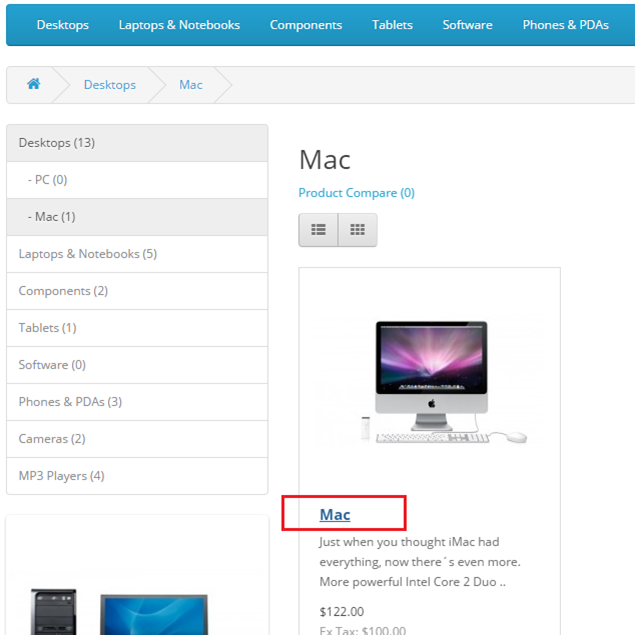
Nhưng bất ngờ thay, trong thực tế bạn nhận được element này:
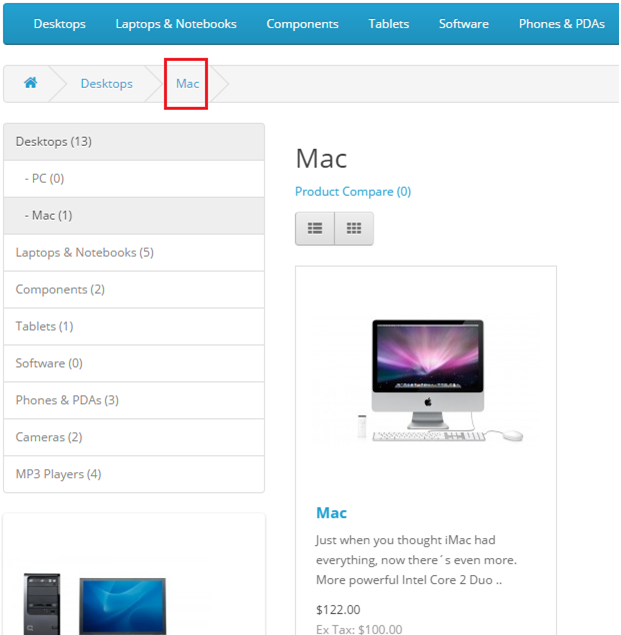
Do vậy, để chắc chắn luôn lấy đúng element, bạn nên đầu tư thời gian mổ xẻ và hiểu rõ về cấu trúc trang web mình đang test. Trong ví dụ trên, bạn có thể dễ dàng phân biệt 2 web elements bằng ancestor của chúng .
XPath của search result (case #1):
//div[@id=’content’]//a[.=’Mac’]
XPath của breadcrumb button (case #2):
//div/ul/li/a[.=’Mac’]
Kết luận
Hy vọng rằng làm sáng tỏ 3 hiểu lầm này có thể giúp bạn hiểu XPath, nhận diện element khi viết test case dễ dàng và test suite của bạn sẽ chạy ổn định hơn.
Bài viết gốc được đăng tải tại vntesters.com
Có thể bạn quan tâm:
- Test Automation — Con đường không dễ dàng với bất kỳ ai
- 04 Điều Cần Chú Ý Cho Người Mới Làm Automation Test
- Designer nên làm gì trong việc tối ưu hiệu năng Website
Xem thêm Việc làm Developer hấp dẫn trên TopDev
- M Martech là gì? Tại sao học ngành marketing nên biết?
- S So sánh chi tiết iOS 18 vs iOS 26: Cuộc cách mạng trên iPhone chỉ sau 1 năm
- B BenQ RD Series – Dòng Màn Hình Lập Trình 4k+ Đầu Tiên Trên Thế Giới
- i iOS 18 có gì mới? Có nên cập nhật iOS 18 cho iPhone của bạn?
- G Gamma AI là gì? Cách tạo slide chuyên nghiệp chỉ trong vài phút
- P Power BI là gì? Vì sao doanh nghiệp nên sử dụng PBI?
- K KICC HCMC x TOPDEV – Bước đệm nâng tầm sự nghiệp cho nhân tài IT Việt Nam
- T Trello là gì? Cách sử dụng Trello để quản lý công việc
- T TOP 10 SỰ KIỆN CÔNG NGHỆ THƯỜNG NIÊN KHÔNG NÊN BỎ LỠ
- T Tìm hiểu Laptop AI – So sánh Laptop AI với Laptop thường